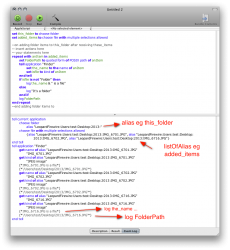
and just for completeness: uploadSOrev again:
I don't know why you say "again", since I don't see it posted at all previously on this thread.
EDIT: that made no sense.
I agree. But maybe not for the same reasons as you.
here's the output:
Code:
Jason$ ./revised /users/Jason/Desktop/place_on_server
chmod: /users/Jason/Desktop/place_on_server/SO/a.out: No such file or directory
rsync: link_stat "/users/Jason/Desktop/place_on_server/SO/a.out" failed: No such file or directory(2)
You're showing the output from a ./revised command, which is presumably a shell script you wrote. Unfortunately, you haven't posted the contents of ./revised.
Your ./revised script is apparently using chmod and rsync, but that's just surmise from the error messages. Anything else, only you know.
Please follow this template:
1. I wrote the following code:
2. It should do the following:
- Describe step by step what it should do.
- Use numbered steps if necessary.
3. I expected the result to be:
Describe expected result here, including expected output.
4. Instead, the actual result was:
Describe actual result here, including actual output.
Without some description of what you
expect to happen, no one knows what
should happen. Yes, we know you're trying to copy files to a server. It's
how the copy should happen that needs to be described.
You have uncommented code, possibly containing some errors in semantics or concept, but since no one knows what it
should do, no one knows whether
what it actually does is correct, or where it's incorrect, what the correct thing is.
Shell syntax is not like most other languages. Many things are allowed, and will do something, but whether that's what is intended or not is a different question. So it's not at all clear whether what actually happens is what you want to happen, or whether something else should happen but you don't know how to express it correctly.
I honestly can't tell what you expect your "hourly" shell script to do, by which I mean the script that begins:
Code:
#!/bin/bash
cd $1
list=$(ls)
It certainly has some interesting uses of commands, such as this:
which is more succinctly expressed as:
I'm also unclear on how you expect certain expressions to evaluate. For example:
The 'then ... fi' block will execute for both values you assign to notfound, i.e.:
Code:
notfound=true
notfound=false
will produce the same result: the block is executed. If that's what you intended, fine, but that then makes me wonder why two values are needed.
If you're not familiar with bash scripting, I wouldn't expect you to know all the details of
[[ expr ]] evaluation. But if you're attempting to write a bash script, I would expect you to know bash well enough to write the script, or at least be referring to the bash man page while writing the script.
It appears to me that you're not testing any of the smaller sub-parts of the script at all. You seem to just be writing the whole thing, running it, and hoping for it to work. Unfortunately, hope alone is a remarkably ineffective debugging strategy.
If you're not already familiar with how bash conditionals work, then you really need to write several different simplified bash scripts, which you can test and then learn what actually happens. Doing so would show exactly what's needed for notfound.
You should learn about the -x option to bash, which causes it to show you the commands being executed. Refer to the bash man page, find the 'set' command description, and look at the -x option description.
You should also make test scripts for things like this:
Code:
( IFS=/; chmod 755 "$*"; rsync "$file" "root@$addr:/var/www/media/$relpath"; )
to make sure that what you expect to happen is actually happening, and there are no strange side effects.
I don't really understand what your general approach is at all. That is, you haven't explained why you have such substantial scripts (uploadSOrev, revised) with lots of directory traversal and pathname building.
You seem to be using 'rsync' to perform the copying, but you also have a bunch of shell-based "find the file, see if it already exists on the server" logic, and that logic doesn't seem to be working. In short, the shell scripting itself appears to be a significant part of the overall problem.
What I'm wondering is why you have any "see if it already exists on the server" logic at all.
I'm pretty sure that rsync is already capable of traversing directory trees and copying things that don't exist at the target location. In other words, if you just gave rsync the base of the directory tree to copy, the target server location, and the correct set of options, it would be able to make the target server directory be an exact duplicate of the source directory. If that's not what you want to happen, then I don't understand what you're trying to accomplish.
There is also a command (find) that is specifically designed to traverse directory trees, evaluate files and directories for a large number of possible conditions, and then either print the path of the file, or run a command with the file.
I don't know if 'find' would be more or less suitable than rsync for doing your traversals, because I don't understand why you have the traversals in the first place. Again, this comes back to a lack of explanation about how you're trying to copy, and exactly what you want the result on the server to be.
At minimum, I suggest breaking the problem down into much smaller shell scripts, which you can individually test for correctness. You should be able to run each of your conditional blocks individually (DIR and F) and then manually confirm it did the correct thing.
If you don't have reliable building-blocks, then anything built with them is itself unreliable.
Rather than writing traversal scripts that actually
run rsync, write scripts that echo out the commands that should be run, along with all the correct arguments. That way you can do some debugging without needing rsync to run correctly. You can also setup "list.txt" files manually, or target files on the server (also manually), and confirm that what happens with any "copy if it doesn't exist on server" logic is behaving properly.
In short, make the traversal observable, then observe it.