Preamble: I learnt of this July 2013 application shortly before Christmas that year. I have been thrown off the scent but still, it interests me. I haven't given it much thought in recent months …
Related: ZFS on Mac OS X
From OS X 10.10 codenamed Syrah (merged):
----
This new topic is focused on the 'Location independent files' patent.
(ZFS should be off-topic; there's a link, above, to an earlier topic about ZFS.)
About the application
Managing data units by converting the data units into data segments and access files describing how to retrieve the data segments using hash values for the data segments. In a data store operation, the data unit is divided into data segments and an access file is generated. The access file includes segmenting scheme information for the data segments, hashing scheme information for the hash values, hash identification information describing the hash values, and location information identifying the locations at which the data segments are available. In a data retrieval operation, data from the data unit is retrieved by accessing the data segments and extracting the data therefrom, where the data segments are retrieved based on the access file for the data unit.
Abstract (français)
L'invention permet de gérer des unités de données en convertissant les unités de données en segments de données et en fichiers d'accès décrivant comment récupérer les segments de données au moyen des valeurs de hachage pour les segments de données. Lors d'une opération d'enregistrement de données, l'unité de données est divisée en segments de données et un fichier d'accès est généré. Le fichier d'accès comprend des informations de schéma de segmentation pour les segments de données, des informations de schéma de hachage pour les valeurs de hachage, des informations d'identification de hachage décrivant les valeurs de hachage, et des informations d'emplacements identifiant les emplacements où les segments de données sont disponibles. Lors d'une opération de récupération de données, les données provenant de l'unité de données sont récupérées en accédant aux segments de données et en extrayant les données de ceux-ci, les segments de données étant récupérés d'après le fichier d'accès pour l'unité de données.
Some links to the application
Apple's 2013 application refers to a 2007 edition of the Wikipedia page for BitTorrent.
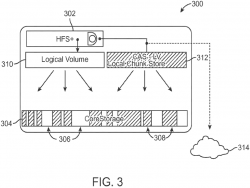
Figure 3 shows CoreStorage (the phrase sometimes used by Apple for Core Storage):
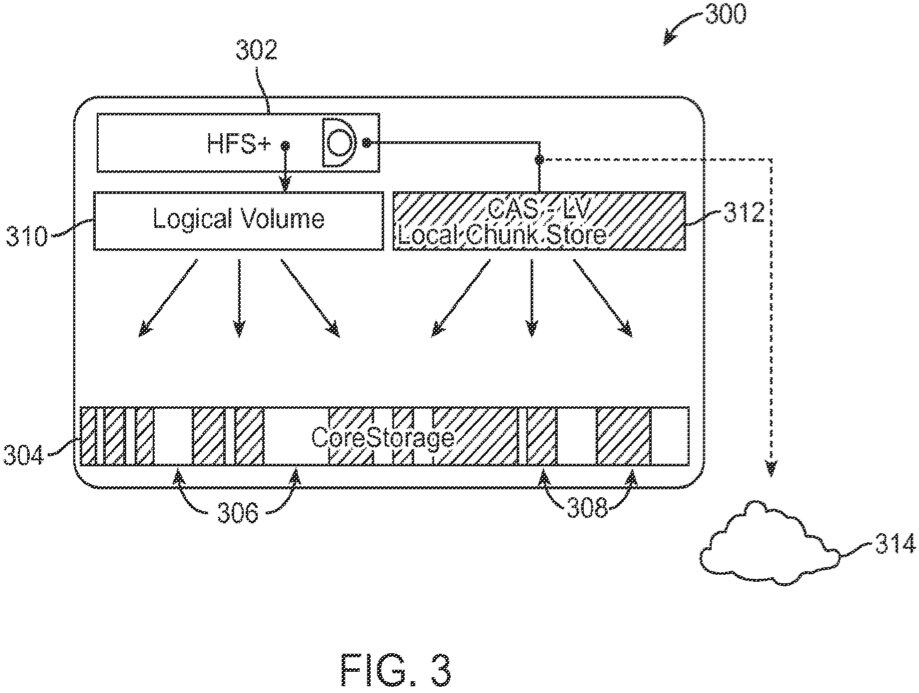
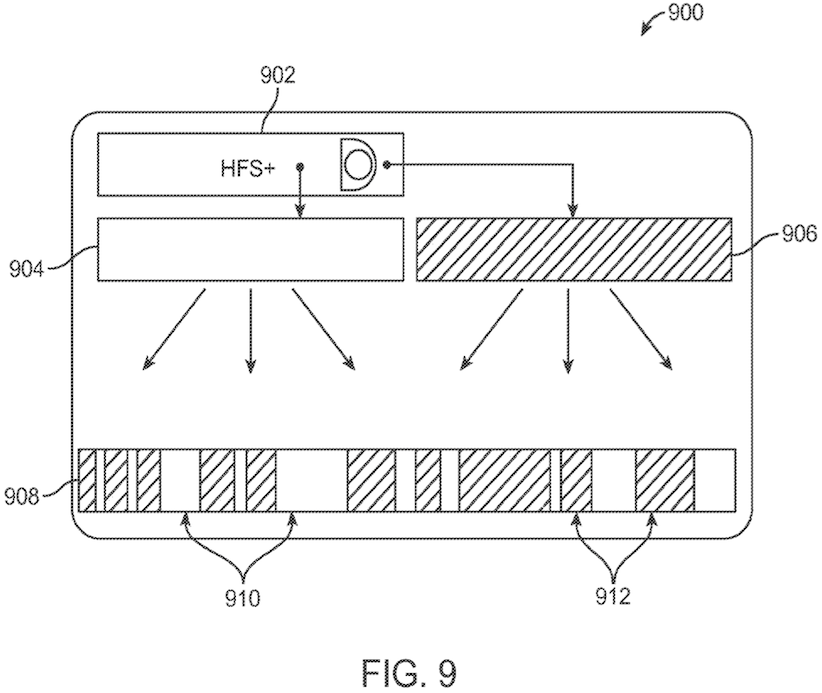
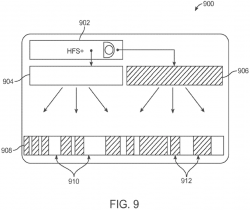
Figure 9 is " a schematic illustration configured in accordance with an alternate embodiment ":
Thoughts (December 2013)
Whether or not the application is granted, I'll be interested to see whether Apple does anything with OS X to benefit from technologies such as this.
Metadata (for Spotlight and the like)
If metadata is generated remotely, then what's generated could be encrypted before transfer to the client computer. But server-side decryption – for any purpose – will be unacceptable to some users.
If metadata is generated only locally – at the place of creation or edition or a file – then I guess that what's generated could be encrypted before transfer to the cloud (iCloud, for example) and never decrypted at a store that's not trusted by the user. Prime examples of trustable stores would be: hardware devices, running iOS or OS X, that are both (a) owned by; and (b) appropriately secured by the creator/editor of the data.
My knowledge of security is quite basic so I'll appreciate other people's thoughts.
Questions
In figures 3 and 9, all arrows are one-way. Are those arrows misrepresentative – should some be two-way?
Later thoughts (February 2014)
Some of what's illustrated is immediately recognisable as Core Storage pooling of local devices with different qualities (e.g. Fusion Drive and the like). Nothing new there, just cod and chips.
Much more tasty: the optional integration with remote storage (cloud) and – illustrated below – the optional purge of locally stored data units.
> interest to people who liked, or wanted more from, iDisk
A simple comparison
With iDisk, an entire volume – a collection of files, with a file system – was in the cloud. You either:
iDisk was effective for some users, but very coarse. Very blunt: either nothing, or the whole lot.
----
With a location independent files approach:
To put things another way … instead of seeing both Macintosh HD and iDisk in the sidebar of Finder, as two separate devices:
Those are oversimplifications – not intended to abstract or summarise the patent application in its entirety! I have not yet attempted to understand the whole thing, the possibilities.
Two figures:
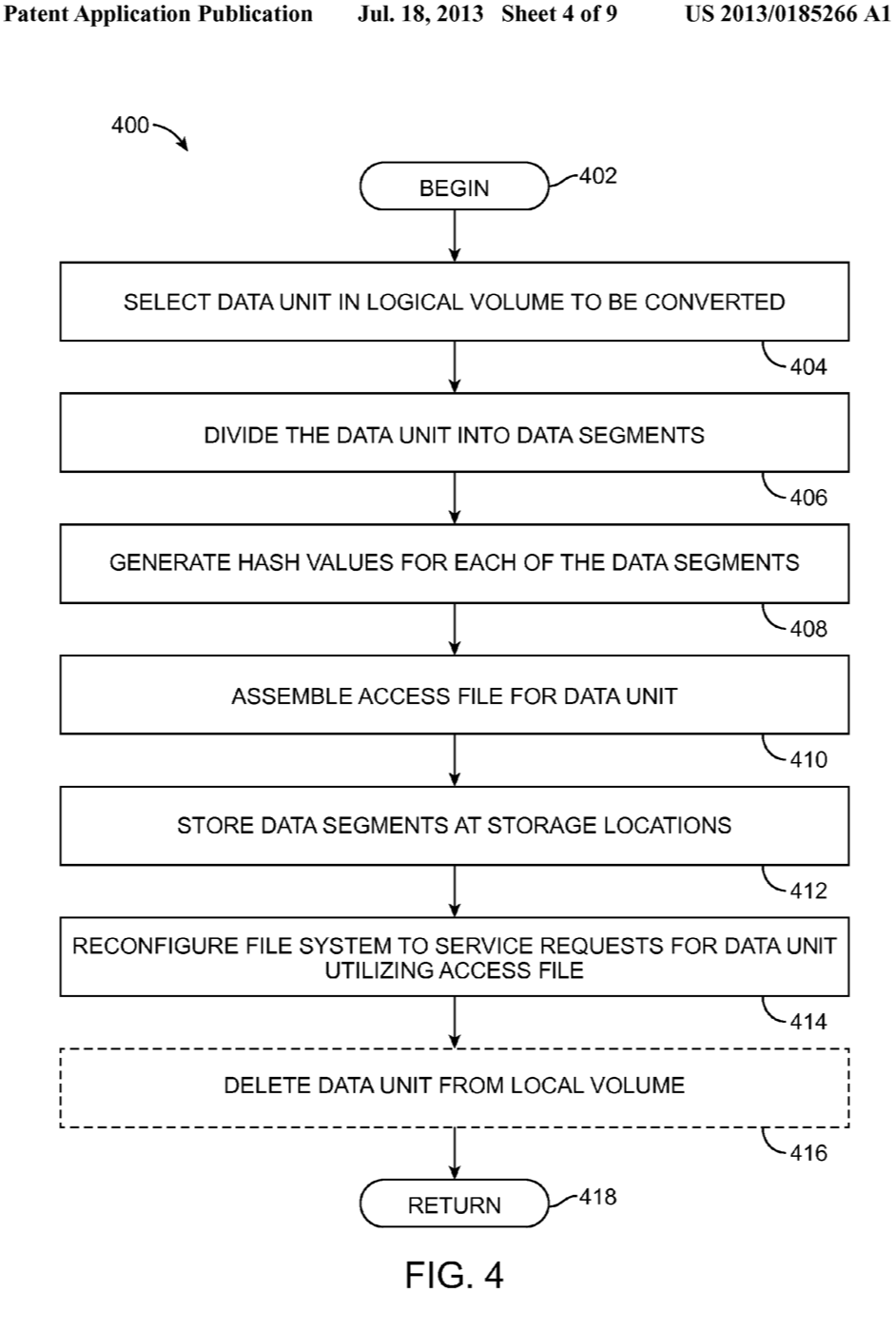
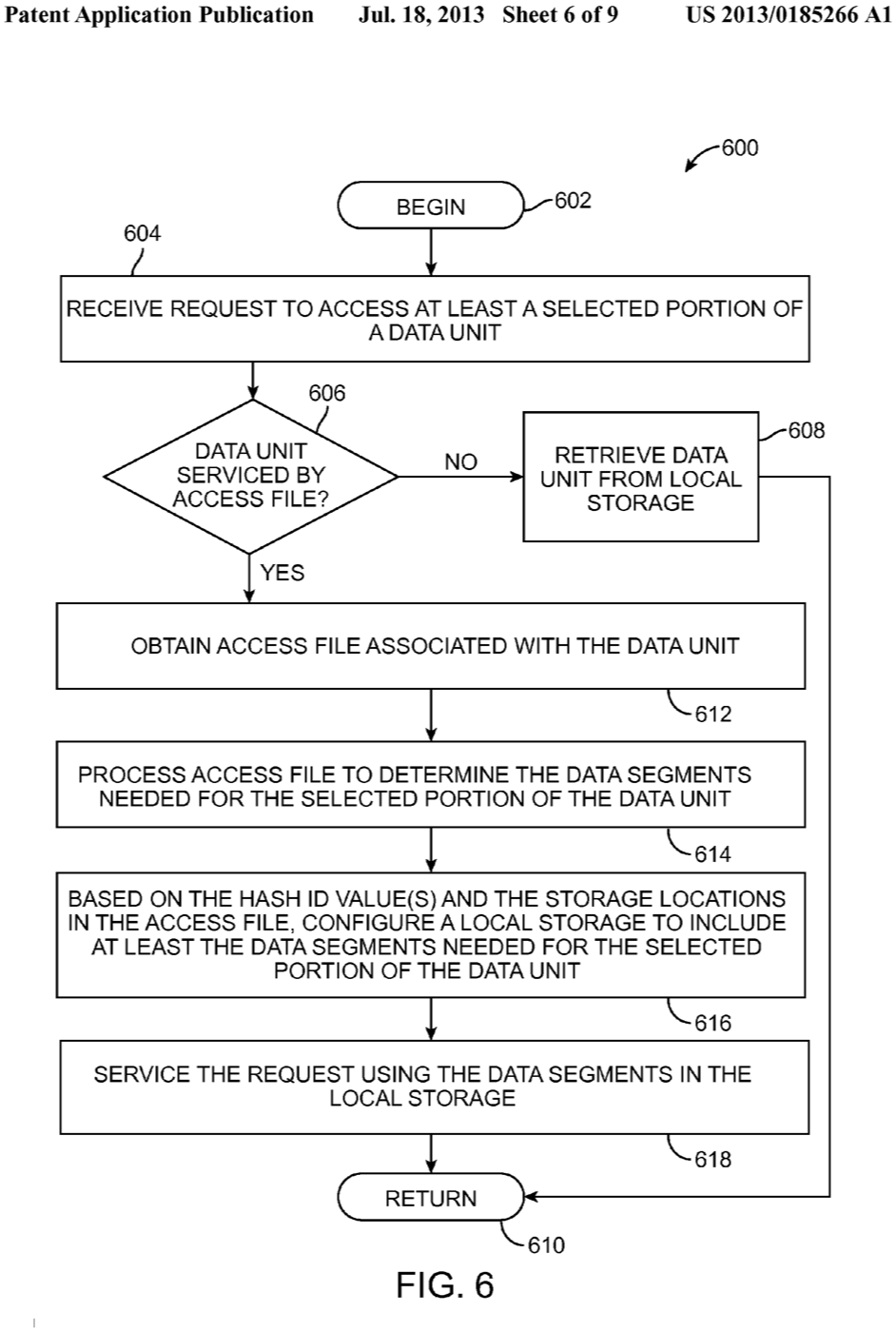
In context:
Brief description of the drawings in the patent application
[0011] FIG. 1 illustrates an example computing device;
[0012] FIG. 2 is a schematic illustration of an embodiment of a configuration of an access file and associated data segments;
[0013] FIG. 3 is a schematic illustration of an embodiment of a computing system;
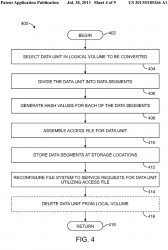
[0014] FIG. 4 is a flow chart of steps in an embodiment of a method for converting a data unit to an access file and associated segments;
[0015] FIG. 5 is a schematic of an embodiment of a system for converting a data unit to an access file and associated segments;
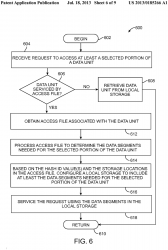
[0016] FIG. 6 is a flow chart of steps in an embodiment of a method for accessing a data unit using an access file and associated segments;
[0017] FIG. 7 is a flow chart of steps in an embodiment of a method for converting an access file and associated segments to a data unit;
[0018] FIG. 8 is a flow chart of steps in an embodiment of a method for generating different versions of a data unit; and
[0019] FIG. 9 is a schematic illustration of an alternate embodiment of a computing system.
Some confusion?
Part [0079] of the patent application seems confused. With emphasis and colours added by me:
"… the first physical device 904 is a storage volume with a high access speed and low storage capacity and
the second physical device 906 is a storage volume with a low access speed and a high storage capacity. For example,
the first physical device 904 can be a magnetic disk drive and
the second physical device 906 can be a solid-state disk drive. …"
----
More likely, in my opinion:
I can't pretend to understand the patent application as a whole, but it seems to me that an implementation:
From summary part [0007]:
"… At a local system, rather than storing the data unit, the access file for the electronic content is stored instead and the local system is configured to service any requests for the data unit using the corresponding access file. Therefore, when access to the data unit is requested by a local system, the access file is utilized to determine what portion of the data unit is needed for fulfilling the request and to determine which of the data segments to retrieve. Further, based on the hashing information in the access file, the needed data segments are retrieved by identifying data segments providing matching hash values. …"
Now, up to two of the claims:
"18. The method of claim 17, wherein the configuring further comprises deleting one or more other data segments not currently in use responsive to the local storage having insufficient space for one or more of the identified data segments.
"19. The method of claim 18, wherein the other data segments are selected for deletion based on at least a history of usage of the other data segments at the computing device."
And down to the last part of the summary:
"[0010] The present technology can also provide enhanced file systems and methods therein. In general, the storage at a computing device generally consists of used and unused portions. The used portions are logically managed by the file system to provide a logical storage for data units stored on the local device. In the present technology, the file system is further configured to utilize the unused portions as storage for data segments retrieved from remote systems. That is, the access files are stored in the logical storage and are used to service requests for the associated data units, as previously described. Data segments are then stored in the unused space and accessed via their hash values. In the event that insufficient space is available for the data segments being retrieved, other data segments can be deleted or overwritten based on priority criteria. Additionally, the file system can be configured to manage the logical storage by data units to and from data segments based on some criteria."
Consider this:
" data segments are retrieved by identifying data segments providing matching hash values. "
Beyond the scope of the patent application: imagine those segments being encrypted. Then multiple users could opt to pool all segments in a remote storage system where segments are de-duplicated. Fewer copies of segments should mean less cost for the provider of the remote system/service, in which case I would expect the provider to charge less to the end user.
I imagine that a primary provider/reseller might be Apple. Hopefully not a sole provider; I'd prefer a system that allows the end user to decide what type of storage device is to be used for pooling his/her remote data segments alongside the segments of friends, of neighbours and so on. That storage device might be a spare hard disk drive ( I reminisce of the potential that Wuala had, then lost).
Within the patent application: " storing the updated access file in a public location " and much talk of hashing.
Food for thought. Almost too much. And the phrase "some criteria" is sufficiently vague that we can't properly guess what, if anything, Apple has up its sleeves.
Related: ZFS on Mac OS X
From OS X 10.10 codenamed Syrah (merged):
The next big change that Apple needs to bring to OS X is a new filesystem. HFS+ harks back to Mac OS classic days, and only existed to provide backwards compatibility with the older system. … As I remember, Apple did hire some filesystem engineers to work on a new system for OS X following the abandonment of the ZFS project, so I am hoping that OS X 10.10, or whatever it will end up being called, will bring this change.
Wonder whether something will be done with the 'Location independent files' patent.
This is a very interesting patent, and it would be awesome if Apple made use of this technology in OS X and iOS!
Yeah, some aspects could be a good fit with continuity.
----
This new topic is focused on the 'Location independent files' patent.
(ZFS should be off-topic; there's a link, above, to an earlier topic about ZFS.)
About the application
- International Publication Number WO/2013/109490 A1
- International Application Number PCT/US2013/021375
- United States Patent Application Publication US 2013/0185266
- Inventors: Deric S. Horn, Jeffrey D. Chung and Wenguang Wang
- Applicant: Apple Inc.
Managing data units by converting the data units into data segments and access files describing how to retrieve the data segments using hash values for the data segments. In a data store operation, the data unit is divided into data segments and an access file is generated. The access file includes segmenting scheme information for the data segments, hashing scheme information for the hash values, hash identification information describing the hash values, and location information identifying the locations at which the data segments are available. In a data retrieval operation, data from the data unit is retrieved by accessing the data segments and extracting the data therefrom, where the data segments are retrieved based on the access file for the data unit.
Abstract (français)
L'invention permet de gérer des unités de données en convertissant les unités de données en segments de données et en fichiers d'accès décrivant comment récupérer les segments de données au moyen des valeurs de hachage pour les segments de données. Lors d'une opération d'enregistrement de données, l'unité de données est divisée en segments de données et un fichier d'accès est généré. Le fichier d'accès comprend des informations de schéma de segmentation pour les segments de données, des informations de schéma de hachage pour les valeurs de hachage, des informations d'identification de hachage décrivant les valeurs de hachage, et des informations d'emplacements identifiant les emplacements où les segments de données sont disponibles. Lors d'une opération de récupération de données, les données provenant de l'unité de données sont récupérées en accédant aux segments de données et en extrayant les données de ceux-ci, les segments de données étant récupérés d'après le fichier d'accès pour l'unité de données.
Some links to the application
- US2013021375 LOCATION INDEPENDENT FILES – World Intellectual Property Association (WIPO)
- United States Patent Application: 0130185266 – United States Patent and Trademark Office
- LOCATION INDEPENDENT FILES - APPLE INC. (PDF) – SumoBrain
- LOCATION INDEPENDENT FILES - Patent application – Patentdocs in the Internet FAQ Archives
Apple's 2013 application refers to a 2007 edition of the Wikipedia page for BitTorrent.
Figure 3 shows CoreStorage (the phrase sometimes used by Apple for Core Storage):
Figure 9 is " a schematic illustration configured in accordance with an alternate embodiment ":
Thoughts (December 2013)
Whether or not the application is granted, I'll be interested to see whether Apple does anything with OS X to benefit from technologies such as this.
Metadata (for Spotlight and the like)
If metadata is generated remotely, then what's generated could be encrypted before transfer to the client computer. But server-side decryption – for any purpose – will be unacceptable to some users.
If metadata is generated only locally – at the place of creation or edition or a file – then I guess that what's generated could be encrypted before transfer to the cloud (iCloud, for example) and never decrypted at a store that's not trusted by the user. Prime examples of trustable stores would be: hardware devices, running iOS or OS X, that are both (a) owned by; and (b) appropriately secured by the creator/editor of the data.
My knowledge of security is quite basic so I'll appreciate other people's thoughts.
Questions
In figures 3 and 9, all arrows are one-way. Are those arrows misrepresentative – should some be two-way?
Later thoughts (February 2014)
Some of what's illustrated is immediately recognisable as Core Storage pooling of local devices with different qualities (e.g. Fusion Drive and the like). Nothing new there, just cod and chips.
Much more tasty: the optional integration with remote storage (cloud) and – illustrated below – the optional purge of locally stored data units.
> interest to people who liked, or wanted more from, iDisk
A simple comparison
With iDisk, an entire volume – a collection of files, with a file system – was in the cloud. You either:
- stored none of the collection locally; or
- stored the entire collection both locally and remotely.
iDisk was effective for some users, but very coarse. Very blunt: either nothing, or the whole lot.
----
With a location independent files approach:
- a collection of data segments can be stored remotely; and
- only the segments that are required (not necessarily an entire file) can be retrieved from remote storage and stored locally
To put things another way … instead of seeing both Macintosh HD and iDisk in the sidebar of Finder, as two separate devices:
- with a location independent files approach, you might see a single device (and you need not care where its bits are stored).
Those are oversimplifications – not intended to abstract or summarise the patent application in its entirety! I have not yet attempted to understand the whole thing, the possibilities.
Two figures:
In context:
Brief description of the drawings in the patent application
[0011] FIG. 1 illustrates an example computing device;
[0012] FIG. 2 is a schematic illustration of an embodiment of a configuration of an access file and associated data segments;
[0013] FIG. 3 is a schematic illustration of an embodiment of a computing system;
[0014] FIG. 4 is a flow chart of steps in an embodiment of a method for converting a data unit to an access file and associated segments;
[0015] FIG. 5 is a schematic of an embodiment of a system for converting a data unit to an access file and associated segments;
[0016] FIG. 6 is a flow chart of steps in an embodiment of a method for accessing a data unit using an access file and associated segments;
[0017] FIG. 7 is a flow chart of steps in an embodiment of a method for converting an access file and associated segments to a data unit;
[0018] FIG. 8 is a flow chart of steps in an embodiment of a method for generating different versions of a data unit; and
[0019] FIG. 9 is a schematic illustration of an alternate embodiment of a computing system.
Some confusion?
Part [0079] of the patent application seems confused. With emphasis and colours added by me:
"… the first physical device 904 is a storage volume with a high access speed and low storage capacity and
the second physical device 906 is a storage volume with a low access speed and a high storage capacity. For example,
the first physical device 904 can be a magnetic disk drive and
the second physical device 906 can be a solid-state disk drive. …"
----
More likely, in my opinion:
- the first physical device 904 is a storage volume with a low access speed and a high storage capacity
- the second physical device 906 is a storage volume with a high access speed and low storage capacity
- " a first storage device; a second storage device having at least one data access metric value higher than a corresponding data access metric value for the first storage device "
- "The system of claim 25, wherein the first storage device is a magnetic disk drive and the second storage device is a solid-state disk drive.".
I can't pretend to understand the patent application as a whole, but it seems to me that an implementation:
- would not require the end user to think about sync, options, preferences or folders
- should allow the end user to be as far as possible carefree
- might go towards allowing reduced cost use of remote storage.
From summary part [0007]:
"… At a local system, rather than storing the data unit, the access file for the electronic content is stored instead and the local system is configured to service any requests for the data unit using the corresponding access file. Therefore, when access to the data unit is requested by a local system, the access file is utilized to determine what portion of the data unit is needed for fulfilling the request and to determine which of the data segments to retrieve. Further, based on the hashing information in the access file, the needed data segments are retrieved by identifying data segments providing matching hash values. …"
Now, up to two of the claims:
"18. The method of claim 17, wherein the configuring further comprises deleting one or more other data segments not currently in use responsive to the local storage having insufficient space for one or more of the identified data segments.
"19. The method of claim 18, wherein the other data segments are selected for deletion based on at least a history of usage of the other data segments at the computing device."
And down to the last part of the summary:
"[0010] The present technology can also provide enhanced file systems and methods therein. In general, the storage at a computing device generally consists of used and unused portions. The used portions are logically managed by the file system to provide a logical storage for data units stored on the local device. In the present technology, the file system is further configured to utilize the unused portions as storage for data segments retrieved from remote systems. That is, the access files are stored in the logical storage and are used to service requests for the associated data units, as previously described. Data segments are then stored in the unused space and accessed via their hash values. In the event that insufficient space is available for the data segments being retrieved, other data segments can be deleted or overwritten based on priority criteria. Additionally, the file system can be configured to manage the logical storage by data units to and from data segments based on some criteria."
Consider this:
" data segments are retrieved by identifying data segments providing matching hash values. "
Beyond the scope of the patent application: imagine those segments being encrypted. Then multiple users could opt to pool all segments in a remote storage system where segments are de-duplicated. Fewer copies of segments should mean less cost for the provider of the remote system/service, in which case I would expect the provider to charge less to the end user.
I imagine that a primary provider/reseller might be Apple. Hopefully not a sole provider; I'd prefer a system that allows the end user to decide what type of storage device is to be used for pooling his/her remote data segments alongside the segments of friends, of neighbours and so on. That storage device might be a spare hard disk drive ( I reminisce of the potential that Wuala had, then lost).
Within the patent application: " storing the updated access file in a public location " and much talk of hashing.
Food for thought. Almost too much. And the phrase "some criteria" is sufficiently vague that we can't properly guess what, if anything, Apple has up its sleeves.
Attachments
Last edited: