So not having high-end option is fine? Good luck with that as those who need high performance dont care about the power consumption.Comparing chip that consume 50W with chip that can draw 700W and complain that it is slow just show that you don't really understand were Apple currently is. I think we finally have some competition to Nvidia dominance. Not really for games, but for AI.
It is kind of funny because Nvidia started with games and ended with AI. Nvidia is not 3T company because of games, it is because of AI chips.
Apple with chiplets can make bigger GPUs than we have seen in M4 family.
Got a tip for us?
Let us know
Become a MacRumors Supporter for $50/year with no ads, ability to filter front page stories, and private forums.
M5 Chip Achieves Impressive Feat in 14-Inch MacBook Pro Speed Test
- Thread starter MacRumors
- Start date
- Sort by reaction score
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Link? Which "Intel Core i7"? There are literally hundreds of them, ranging from around 12 years. Some of which are two core low-power CPUs.Geekbench 6 shows the Intel Core i7 as nearly 50% faster. What am I missing?
Extremely vague comment
Please explain how Blender is CPU intensive, I'm dying to hear.LOL, Blender is CPU intensive software and you literally admitted that Apple GPU sucks by comparing M3 Ultra to RTX 4070 and 5070. Remember, Apple compared M1 Max to 90 series.
These benchmarks are specifically for benchmarking rendering using the GPU, including ray tracing, in real world scenarios, so it's about as good a benchmark as you're going to get.
Last edited:

It shows not to much sense. My M4 Mac mini plays a bit better BG3 than my 5700XT iMacFinally the base M5 has the same Metal score than my 5700XT iMac. Looking forward to the M5 Max
Exactly. Why ever a „news and rumors“ site should report on a new product that was rumored to be released this week and confirm the new specs instead of leaving us to guess if the rumors are true…Every year new m chip gets released will always show as impressive than the last m chip. I don’t get the point of articles like this. When we know it will be impressive than the last one.
I don’t usually upgrade until it’s 2x as that is honestly where you will notice it in everything you do, not just some things. And usually when it’s 2x, all sorts of other improvements went with it in the same model tier that make all other things 2x or more, like networking, disk access and storage capacity, graphics speed, memory speed and capacity, etc.Just ran GB6 on my M1 Max:
SC: 2322
MC: 12183
Looks like the M6 series will get us to full 2x on single core. M5 is close to 2x but not quite. (We're already there on MC of course).
So as an M1 Pro owner, I may go for the M5 Pro as basically everything about it is going to be 2x or more, other than single core being almost 2x.
Yeah, I can’t use my old Intel Mac mini because it doesn’t understand 2 factor authentication so I can’t login to accounts. And no web pages are secure. And I can’t even go to Apple’s website to get a newer OS to maybe get it to work.I kinda know what will get me according to past examples with Intel Macs.
I sit on latest macos but refuse to do macos26 because nerfing is real. So since i sit on a previous macos, there will be day when it will be an OS issued many years ago. Simply put my old intel mac stopped opening web pages in safari, my software updates started requiring newer os or new installs were totally for newer os.
I hacked it by using chrome, but two years later that thing needed to update to open my banking apps but the update required newer os.
That is when i got a new laptop, even though the last one never glitched.
The most interesting in M5 is GPU. If we look at blender benchmarks M5 is faster than M1 Ultra. It seems that in M1 family of chips GPU wasn't the strongest in compute. That is about to change with M5 quite a lot.

 opendata.blender.org
opendata.blender.org
Blender - Open Data
Blender Open Data is a platform to collect, display and query the results of hardware and software performance tests - provided by the public.
opendata.blender.org
M1 series didn't have any raytracing hardware, so I think that is going to make up a large percentage of the difference.The most interesting in M5 is GPU. If we look at blender benchmarks M5 is faster than M1 Ultra. It seems that in M1 family of chips GPU wasn't the strongest in compute. That is about to change with M5 quite a lot.
Blender - Open Data
Blender Open Data is a platform to collect, display and query the results of hardware and software performance tests - provided by the public.
Dragging along my 2017 Intel MBP, I was hoping for an M5 Pro or max. I need performance cores and the stock M5 won’t be enough. It’s gotten bad enough that I just need a new machine and may cave and go for an M4 Pro. The rumeurs on the M5 Pro seem to be all over the place. If it’s next spring, maybe can chug along th final mile but if w’ere waiting until next fall, forget it.
Which is it? You're able to use a 2017 Intel MBP (presumably i7-7820hq variety, not the i5), or you need performance cores, and a stock M5 won't do?Dragging along my 2017 Intel MBP, I was hoping for an M5 Pro or max. I need performance cores and the stock M5 won’t be enough. It’s gotten bad enough that I just need a new machine and may cave and go for an M4 Pro. The rumeurs on the M5 Pro seem to be all over the place. If it’s next spring, maybe can chug along th final mile but if w’ere waiting until next fall, forget it.
I have a Mac Mini M4 for heavy lifting, I want a nearer equivalent in my second machine. The 2017 is only used at present for MS office, browsing and looking at photos (no heavy lifting). I use Logic Pro which is very hungry for P cores. So M5 has 4, M4 Pro 10 - that will be significant improvement.Which is it? You're able to use a 2017 Intel MBP (presumably i7-7820hq variety, not the i5), or you need performance cores, and a stock M5 won't do?
Should have replaced this a while ago. Laptop life-span really is at most 4-5 years. Grinding along just for the sake of « holding on doesn’t make much sense. So M4 Pro vs « rumored » M5 pro - I lose what, 6-9 months? Sort of what I am thinking at the moment …
Happy to be convinced otherwise …
Yeah, that's a hard call. It seems the big overhaul on the M5 is the GPU, and Logic is hungry for CPU. As you say, grinding for the sake of holding on doesn't make much sense.I have a Mac Mini M4 for heavy lifting, I want a nearer equivalent in my second machine. The 2017 is only used at present for MS office, browsing and looking at photos (no heavy lifting). I use Logic Pro which is very hungry for P cores. So M5 has 4, M4 Pro 10 - that will be significant improvement.
If your current M4 is able to handle your workload, just not ideally, you should be set with the M4 Pro... but you know it's days are numbered, so paying full price as it's about to be replaced isn't appealing... and who knows what other benefits the new chips might have on top of the extra CPU power. Early M5 benchmarks are showing improved SSD speeds, which would be a nice bonus if that holds true on all systems... but none of the improvements are strictly needed. It seems the wait for the M5 Pro is more FOMO than need. I guess whether waiting is worthwhile depends on how much you hate limping along on your 2017 MBP. Assuming you're in the US, B&H and other big vendors often have massive sales. Maybe you can find a deal on an M4 Max, instead... extra power without waiting.
70 series are not even the best GPU. Where is 5080 or 5090? Ultra series are the only best option for Apple which is only 70 series level. Clearly, you admitted yourself that Apple GPU sucks. If you cant compare with 90 series, then it only proves me right.
It’s not the first time PC fanatics on a Mac site think Apple or their GPUs suck and I’m not here to change your mind but you have much to learn. Your only argument is ”Apple GPUs suck” and that’s obviously just emotional, not rational or factual. You can pretend I admitted if it makes you feel good but I didn’t because there’s nothing to admit to. You simply make things up.
So let’s not move the goalposts again; You said M4 series GPUs are not even close to RTX 40 series, I showed they’re close and above. You said Apple can’t even make a high-end GPU, I showed M4 Max/Ultra can compete with Nvidia high-end GPUs. Everybody knows Apple doesn’t have a GPU that can compete with the top-end desktop GPUs like 5090, 4090 or 5080 so what’s your point?
Have you seen Apple comparing Apple Silicon to RTX 5090? It’s not Apple’s goal to make power hungry monster GPU cards with lots of problems like melting power connector, incomplete dies and missing ROPs, black screen, bad driver quality and stability and only 7% faster than the previous gen, not up to 60% like M5.
Only PC/Nvidia fans compare iGPUs with dGPUs when it comes to Apple. It’s like telling a body builder you suck at 100m or a gymnast they suck in Strongmen. By your definition all AMD and Intel GPUs suck too. So Nvidia is the king, you think you discovered something new and never unseen?
Where is 5080/5090? I just told you. Ultra is right above 5080 M and 4090 M where it should be. It’s ridiculous to say it sucks because it’s not on par with a top-end 575W desktop GPU like 5090. For professional work like LLM 72b M4 Max with 128GB is twice as fast as a $7000 card like RTX 6000 Ada 48GB and over 12 times faster than 4090 24GB according to Geekerwan when you need lots of VRAM.
Again, we’ll see in the spring. It would be the first time that Apple catches up to Nvidia. By the way the most common GPU on Steam right now is 3060. Only 0.82% use 5080 and 0.31% use 5090.
You were wrong about everything. If you think Apple GPUs suck be my guest but don’t expect to be taken seriously.
Your logic already failed when Mac is worst platform for GPU intensive software where most of them dont even support. Your example doesn't prove anything in real life and doesn't change the fact that people use Nvidia for 3D, AI, and research rather than Mac. Also, where are those results with 90 series and above?It’s not the first time PC fanatics on a Mac site think Apple or their GPUs suck and I’m not here to change your mind but you have much to learn. Your only argument is ”Apple GPUs suck” and that’s obviously just emotional, not rational or factual. You can pretend I admitted if it makes you feel good but I didn’t because there’s nothing to admit to. You simply make things up.
So let’s not move the goalposts again; You said M4 series GPUs are not even close to RTX 40 series, I showed they’re close and above. You said Apple can’t even make a high-end GPU, I showed M4 Max/Ultra can compete with Nvidia high-end GPUs. Everybody knows Apple doesn’t have a GPU that can compete with the top-end desktop GPUs like 5090, 4090 or 5080 so what’s your point?
Have you seen Apple comparing Apple Silicon to RTX 5090? It’s not Apple’s goal to make power hungry monster GPU cards with lots of problems like melting power connector, incomplete dies and missing ROPs, black screen, bad driver quality and stability and only 7% faster than the previous gen, not up to 60% like M5.
Only PC/Nvidia fans compare iGPUs with dGPUs when it comes to Apple. It’s like telling a body builder you suck at 100m or a gymnast they suck in Strongmen. By your definition all AMD and Intel GPUs suck too. So Nvidia is the king, you think you discovered something new and never unseen?
Where is 5080/5090? I just told you. Ultra is right above 5080 M and 4090 M where it should be. It’s ridiculous to say it sucks because it’s not on par with a top-end 575W desktop GPU like 5090. For professional work like LLM 72b M4 Max with 128GB is twice as fast as a $7000 card like RTX 6000 Ada 48GB and over 12 times faster than 4090 24GB according to Geekerwan when you need lots of VRAM.
Again, we’ll see in the spring. It would be the first time that Apple catches up to Nvidia. By the way the most common GPU on Steam right now is 3060. Only 0.82% use 5080 and 0.31% use 5090.
You were wrong about everything. If you think Apple GPUs suck be my guest but don’t expect to be taken seriously.
Mac is only good for THEORATICAL performance while literally there aren't many GPU intensive software to run on Mac which is such a pity. Again, benchmark doesn't prove anything especially since you cant even compare with 90 series which Ultra series suppose to compete with according to Apple officially.
Also, isn't it MORE logical that people would ditch and use Mac if it's really that powerful? At this point, your statement is false and even if it's true, only a tiny amount of people would really use Mac for GPU intensive software.
Last edited:
Your logic already failed when Mac is worst platform for GPU intensive software where most of them dont even support. Your example doesn't prove anything in real life and doesn't change the fact that people use Nvidia for 3D, AI, and research rather than Mac. Also, where are those results with 90 series and above?
Mac is only good for THEORATICAL performance while literally there aren't many GPU intensive software to run on Mac which is such a pity. Again, benchmark doesn't prove anything especially since you cant even compare with 90 series which Ultra series suppose to compete with according to Apple officially.
Also, isn't it MORE logical that people would ditch and use Mac if it's really that powerful? At this point, your statement is false and even if it's true, only a tiny amount of people would really use Mac for GPU intensive software.
Well, your logic failed when you had to move the goalposts after you were proven wrong. Apple GPUs not being best at some things doesn’t mean they ”suck” at everything.
Theoretical performance? You didn’t know Blender Render is GPU intensive and so are local LLMs which use the GPU and VRAM primarily to be as fast as possible. If you use CPU and RAM it will be very slow. My examples are from real life where 3D artists use Blender and AI developers use advanced LLMs but you say they don’t prove ”anything”? So Blender is not 3D and LLM is not AI? Get real for once!
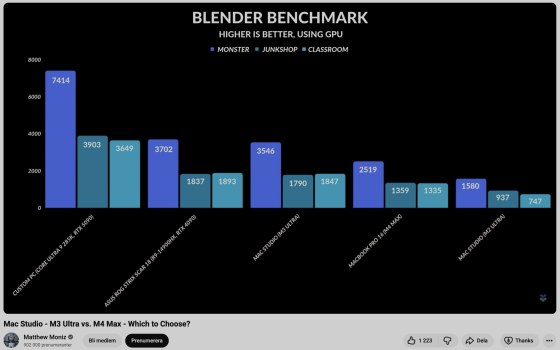
Here is M3 Ultra faster than 5080 M and 4090 M laptops (Gigabyte, Razer Blade) in ”real-life” Blender scenes (Monster, Junkshop, Classroom) as I wrote:
There are ”literally” many GPU intensive applications for 3D, AI, game development and more for Mac. Naturally there are more for Windows but to say ”literally” means you neither have googled nor heard of 3D Slash, 4A Engine, Anvil Engine (Ubisoft), Asura Engine (Rebellion), AutoCAD, Blender, Clausewitz (Paradox), Cedreo, Cinema 4D, DeepSeek, Divinity Engine (Larian), FreeCAD, Fusion360, Gemma, Godot, Houdini, Llama, Lightwave 3D, LM Studio, Magicavoxel, Maya, Meshmixer, Modo, Northlight Engine (Remedy), Ollama, OnShape, Poser, Qwen, Red Engine (CDPR), RE Engine (Capcom), Rhino, Roblox Studio, SelfCAD, SketchUp, TinkerCAD, Unity, Unreal Engine and ZBrush.
Nobody’s trying to change the fact that people use Nvidia. People can use whatever they want for their needs. That doesn’t either change the fact that Apple’s GPUs DON’T suck at everything. They’re the second best GPUs in Blender. What actually ”suck” are all the GPUs from AMD and Intel. RX 9070 XT is slower than base M3 Max and RX 7900 XTX slower than base M4 Max. Arc A770 is even slower than M4 Pro 20c.
It’s also clear that Nvidia RTX 50 series ”suck” at big local LLMs. You can even run a 404GB DeepSeek R1 model on a single M3 Ultra but would need multi-GPU setups with several high-end Nvidia graphics cards that devour thousands of watts of electricity and cost enormous amount of money for the same task. M3 Ultra is 7x faster than a single 5090 running that 404GB model thanks to its large unified memory and VRAM. Here is that LLM 72b result I was talking about:
RTX 5090
Mac Studio M3 Ultra with 512GB RAM/VRAM costs $9500. If you wanted to match that amount of memory for LLM you would have to buy
16x RTX 5090 32GB $3000 = $48,000
11x RTX Pro 5000 48GB $4600 = $50,600
7x RTX Pro 5000 72GB $5000 = $30,000
6x RTX Pro 6000 96GB $8600 - 10000 = $51,600 - $60,000
7x H100 80GB $30,000 = $210,000
Notice that those Nvidia prices are only for the GPUs alone, not for a whole system/computer. For $57,000 you could also buy 6 Mac Studio M3 Ultra and use them in a cluster with MLX and get 3TB VRAM. You could also just buy a M4 Max 128GB that costs $3500 instead of 4x 5090 32GB for $12,000.
Apple has never compared M3 Ultra to RTX 5090 or any other card in the 50 series so that’s a false claim until you provide a source.
People do ditch Nvidia and choose Macs for different reasons. Here is why some developers use Apple instead of Nvidia for LLM.
There is nothing false about my statements because I have data and facts that back them up. My statements were never about people mostly using Macs for 3D, AI and research.
Since you keep forgetting your original claims I remind you for the third time. You said ”M4 series GPUs are not even close to RTX 40 series” and ”Apple can’t even make a high-end GPU”. I showed none of that is true. Instead of generalizing try to be more precise in your claims next time and don’t spread misinformation.
Last edited:
I always enjoy reading posts where a troll gets utterly ownedWell, your logic failed when you had to move the goalposts after you were proven wrong. Apple GPUs not being best at some things doesn’t mean they ”suck” at everything.
Theoretical performance? You didn’t know Blender Render is GPU intensive and so are local LLMs which use the GPU and VRAM primarily to be as fast as possible. If you use CPU and RAM it will be very slow. My examples are from real life where 3D artists use Blender and AI developers use advanced LLMs but you say they don’t prove ”anything”? So Blender is not 3D and LLM is not AI? Get real for once!
Here is M3 Ultra faster than 5080 M and 4090 M laptops (Gigabyte, Razer Blade) in ”real-life” Blender scenes (Monster, Junkshop, Classroom) as I wrote:
View attachment 2577246View attachment 2577247
There are ”literally” many GPU intensive applications for 3D, AI, game development and more for Mac. Naturally there are more for Windows but to say ”literally” means you neither have googled nor heard of 3D Slash, 4A Engine, Anvil Engine (Ubisoft), Asura Engine (Rebellion), AutoCAD, Blender, Clausewitz (Paradox), Cedreo, Cinema 4D, DeepSeek, Divinity Engine (Larian), FreeCAD, Fusion360, Gemma, Godot, Houdini, Llama, Lightwave 3D, LM Studio, Magicavoxel, Maya, Meshmixer, Modo, Northlight Engine (Remedy), Ollama, OnShape, Poser, Qwen, Red Engine (CDPR), RE Engine (Capcom), Rhino, Roblox Studio, SelfCAD, SketchUp, TinkerCAD, Unity, Unreal Engine and ZBrush.
Nobody’s trying to change the fact that people use Nvidia. People can use whatever they want for their needs. That doesn’t either change the fact that Apple’s GPUs DON’T suck at everything. They’re the second best GPUs in Blender. What actually ”suck” are all the GPUs from AMD and Intel. RX 9070 XT is slower than base M3 Max and RX 7900 XTX slower than base M4 Max. Arc A770 is even slower than M4 Pro 20c.
It’s also clear that Nvidia RTX 50 series ”suck” at big local LLMs. You can even run a 404GB DeepSeek R1 model on a single M3 Ultra but would need multi-GPU setups with several high-end Nvidia graphics cards that devour thousands of watts of electricity and cost enormous amount of money for the same task. M3 Ultra is 7x faster than a single 5090 running that 404GB model thanks to its large unified memory and VRAM. Here is that LLM 72b result I was talking about:
View attachment 2577248View attachment 2577249
RTX 5090
View attachment 2577250
Mac Studio M3 Ultra with 512GB RAM/VRAM costs $9500. If you wanted to match that amount of memory for LLM you would have to buy
16x RTX 5090 32GB $3000 = $48,000
11x RTX Pro 5000 48GB $4600 = $50,600
7x RTX Pro 5000 72GB $5000 = $30,000
6x RTX Pro 6000 96GB $8600 - 10000 = $51,600 - $60,000
7x H100 80GB $30,000 = $210,000
Notice that those Nvidia prices are only for the GPUs alone, not for a whole system/computer. For $57,000 you could also buy 6 Mac Studio M3 Ultra and use them in a cluster with MLX and get 3TB VRAM. You could also just buy a M4 Max 128GB that costs $3500 instead of 4x 5090 32GB for $12,000.
Apple has never compared M3 Ultra to RTX 5090 or any other card in the 50 series so that’s a false claim until you provide a source.
People do ditch Nvidia and choose Macs for different reasons. Here is why some developers use Apple instead of Nvidia for LLM.
There is nothing false about my statements because I have data and facts that back them up. My statements were never about people mostly using Macs for 3D, AI and research.
Since you keep forgetting your original claims I remind you for the third time. You said ”M4 series GPUs are not even close to RTX 40 series” and ”Apple can’t even make a high-end GPU”. I showed none of that is true. Instead of generalizing try to be more precise in your claims next time and don’t spread misinformation.
LOL, you failed to prove it again.Well, your logic failed when you had to move the goalposts after you were proven wrong. Apple GPUs not being best at some things doesn’t mean they ”suck” at everything.
Theoretical performance? You didn’t know Blender Render is GPU intensive and so are local LLMs which use the GPU and VRAM primarily to be as fast as possible. If you use CPU and RAM it will be very slow. My examples are from real life where 3D artists use Blender and AI developers use advanced LLMs but you say they don’t prove ”anything”? So Blender is not 3D and LLM is not AI? Get real for once!
Here is M3 Ultra faster than 5080 M and 4090 M laptops (Gigabyte, Razer Blade) in ”real-life” Blender scenes (Monster, Junkshop, Classroom) as I wrote:
View attachment 2577246View attachment 2577247
There are ”literally” many GPU intensive applications for 3D, AI, game development and more for Mac. Naturally there are more for Windows but to say ”literally” means you neither have googled nor heard of 3D Slash, 4A Engine, Anvil Engine (Ubisoft), Asura Engine (Rebellion), AutoCAD, Blender, Clausewitz (Paradox), Cedreo, Cinema 4D, DeepSeek, Divinity Engine (Larian), FreeCAD, Fusion360, Gemma, Godot, Houdini, Llama, Lightwave 3D, LM Studio, Magicavoxel, Maya, Meshmixer, Modo, Northlight Engine (Remedy), Ollama, OnShape, Poser, Qwen, Red Engine (CDPR), RE Engine (Capcom), Rhino, Roblox Studio, SelfCAD, SketchUp, TinkerCAD, Unity, Unreal Engine and ZBrush.
Nobody’s trying to change the fact that people use Nvidia. People can use whatever they want for their needs. That doesn’t either change the fact that Apple’s GPUs DON’T suck at everything. They’re the second best GPUs in Blender. What actually ”suck” are all the GPUs from AMD and Intel. RX 9070 XT is slower than base M3 Max and RX 7900 XTX slower than base M4 Max. Arc A770 is even slower than M4 Pro 20c.
It’s also clear that Nvidia RTX 50 series ”suck” at big local LLMs. You can even run a 404GB DeepSeek R1 model on a single M3 Ultra but would need multi-GPU setups with several high-end Nvidia graphics cards that devour thousands of watts of electricity and cost enormous amount of money for the same task. M3 Ultra is 7x faster than a single 5090 running that 404GB model thanks to its large unified memory and VRAM. Here is that LLM 72b result I was talking about:
View attachment 2577248View attachment 2577249
RTX 5090
View attachment 2577250
Mac Studio M3 Ultra with 512GB RAM/VRAM costs $9500. If you wanted to match that amount of memory for LLM you would have to buy
16x RTX 5090 32GB $3000 = $48,000
11x RTX Pro 5000 48GB $4600 = $50,600
7x RTX Pro 5000 72GB $5000 = $30,000
6x RTX Pro 6000 96GB $8600 - 10000 = $51,600 - $60,000
7x H100 80GB $30,000 = $210,000
Notice that those Nvidia prices are only for the GPUs alone, not for a whole system/computer. For $57,000 you could also buy 6 Mac Studio M3 Ultra and use them in a cluster with MLX and get 3TB VRAM. You could also just buy a M4 Max 128GB that costs $3500 instead of 4x 5090 32GB for $12,000.
Apple has never compared M3 Ultra to RTX 5090 or any other card in the 50 series so that’s a false claim until you provide a source.
People do ditch Nvidia and choose Macs for different reasons. Here is why some developers use Apple instead of Nvidia for LLM.
There is nothing false about my statements because I have data and facts that back them up. My statements were never about people mostly using Macs for 3D, AI and research.
Since you keep forgetting your original claims I remind you for the third time. You said ”M4 series GPUs are not even close to RTX 40 series” and ”Apple can’t even make a high-end GPU”. I showed none of that is true. Instead of generalizing try to be more precise in your claims next time and don’t spread misinformation.
You said there are many GPU intensive software and yet, only Six of them have more Mac users then Windows which are Ollama, LM Studio, Llama, Qwen, Gemma, DeepSeek and all of them are LLM, not even related to GPU intensive software. Others are Windows focused which fail to prove your point. Supporting those apps does NOT mean they are Mac focused. Literally, how many people would use Mac over Windows for GPU intensive software? I checked ChatGPT search and now, I can clearly disapprove your false info.
Whenever people claim that Apple is good only with LLM, what a joke. Who would run that with a single Mac compared to servers or super computers or even AI farms? Can Mac do that? NO. Besides, why do you keep ignoring slow memory bandwidth comparing those GPU? The memory size is NOT everything. LLM is a tiny part of AI and regardless, it can only do LLM.
While you claimed that Apple GPU isn't sucks and not even close to RTX 40 series, literally none of them proves anything. Is it really hard to compare them with actual games and software, not benchmarks? I said that already.
Besides, you compared Mac Studio to laptops. Laptop RTX 4090 = desktop RTX 4070 which again proved my point. Apple GPU sucks. Good luck with proving your point with false and misleading info.
In real world performance, someone who has the M4, maybe even the M3 or M2, will likely notice very little, if any difference in their normal day-to-day usage.
Its just the more 'pro' users, or those using editing or rendering apps that would notice a slight decrease in rendering times, although whether that is worth the replacement cost is a personal choice......
Its just the more 'pro' users, or those using editing or rendering apps that would notice a slight decrease in rendering times, although whether that is worth the replacement cost is a personal choice......
LOL, you failed to prove it again.
I see you keep showing your great despise for everything Apple with your ”Apple sucks” and ”What a joke” even in your new posts in other threads.
No I didn’t fail, but you failed to understand again. I proved exactly what I intended to prove. Your whataboutism and moving the goalposts were never a part of that. Ignoring and denying simple facts just hurts your credibility more each time.
You said there are many GPU intensive software and yet, only Six of them have more Mac users then Windows which are Ollama, LM Studio, Llama, Qwen, Gemma, DeepSeek and all of them are LLM, not even related to GPU intensive software. Others are Windows focused which fail to prove your point. Supporting those apps does NOT mean they are Mac focused. Literally, how many people would use Mac over Windows for GPU intensive software? I checked ChatGPT search and now, I can clearly disapprove your false info.
You’re literally saying first what I said but still try to make a point of what I didn’t say? This wasn’t a contest about which platform has most users and is irrelevant to the original discussion about your first claims. Everybody knows there are more Windows users in the world or in 3D, AI and gaming, so what? My info was never ”false” because it was neither about ”Mac focused” SW nor about more people choosing Mac rather than PC. This clearly disapproves your pointless argument.
Your claim was ”Mac is worst platform for GPU intensive software where most of them dont even support” and I listed many popular GPU intensive applications that do support Mac, both in 3D, AI and game development. You provided no source for your claim about most of those applications not supporting Mac. I even showed that AMD and Intel GPUs are much worse in Blender Render than Apple’s so that fact also refutes your claim about ”worst platform”.
You’re claiming again falsely that LLM and its related applications are not GPU intensive despite my explanations which shows you’re ignoring the facts again. Below is another screenshot from Alex Ziskind’s channel showing the GPU working at 100%.
It’s quite amusing to see that you check the facts with ChatGPT but still make such false claims. Why don’t you ask ChatGPT ”Is LLM CPU or GPU intensive?” and see which answer you get. I make it easy for you and share the answers below:
- Large Language Models (LLMs) like me (ChatGPT) are GPU-intensive, not CPU-intensive.
- LLMs involve billions of matrix multiplications during both training and inference. These operations are highly parallelizable, which GPUs are optimized for.
- GPUs provide 10×–100× speedups compared to CPUs for LLM workloads.
- GPUs use high-bandwidth VRAM to store model weights and intermediate tensors. If a model doesn’t fit in GPU memory, performance plummets as data is swapped between GPU and CPU memory.
- Training: Extremely GPU-intensive; often uses multiple GPUs or clusters.
- Inference: Still GPU-intensive, though small models can run on CPU if speed isn’t critical.
- LLMs are overwhelmingly GPU-intensive, with CPUs handling orchestration and I/O rather than the math.
The same goes for 3D and game development software. The question wasn’t about the number of users but you claimed most such applications don’t support Mac. I mentioned many popular programs that do support Mac and are used frequently.
Whenever people claim that Apple is good only with LLM, what a joke. Who would run that with a single Mac compared to servers or super computers or even AI farms? Can Mac do that? NO. Besides, why do you keep ignoring slow memory bandwidth comparing those GPU? The memory size is NOT everything. LLM is a tiny part of AI and regardless, it can only do LLM.
The joke is on you for moving the goalposts all the time when you’re proven wrong, spreading disinformation, ignoring facts/explanations and not even bothering to ask your ChatGPT. Who said that Apple is only good with LLM? Not me; I even shared many Blender results debunking your first claims about ”M4 series GPUs are not even close to RTX 40 series” and ”Apple can’t even make a high-end GPU”. Again you’re the only one making the claim that ”Apple is good only with LLM”.
The discussion wasn’t either about servers, super computers and AI farms and whether Macs can do that so all that is irrelevant and ridiculous. So now you have to compare a Mac with supercomputers to make a point? Of course a Mac ”sucks” compared to a supercomputer. What did you expect? Can RTX 5090 do what a supercomputer does? No!
Who would run local LLMs and why instead of cloud solutions? Maybe you should ask ChatGPT again:
- Privacy & Security: Your data stays local. Nothing you type leaves your machine, which is crucial for sensitive or proprietary information (e.g., legal, medical, business data). No cloud dependency means no risk of data leaks via APIs or third-party servers.
- Offline Access: You can use the model without an internet connection, perfect for air-gapped systems, field work, or locations with poor connectivity.
- Cost Control: Once set up, a local model has no per-token or subscription costs. Great for high-volume use (e.g., generating large text batches, code, or documents).
- Customization & Control: You can fine-tune or prompt-engineer your own model for your domain (legal, medical, creative, etc.). Freedom to modify system prompts, memory, or architecture — things that are locked in cloud models. You can even chain it with other local tools (e.g., embeddings, vector DBs, custom APIs).
- Latency & Speed: Once loaded into memory, responses can be faster than remote APIs (no network delay), especially for smaller models optimized for your hardware.
- Transparency & Experimentation: You can inspect what the model does — weights, tokenization, inference process. Perfect for research, education, and AI development without external restrictions.
So first you complain about me using ”benchmarks” and ask for real-life tests but now you ignore real-life Blender and LLM tests and start to compare GPU specs? Memory bandwidth wasn’t even discussed to begin with. Yes, 5090 is faster when it comes to smaller LMs but I’ve been talking about local LLMs that require far more than 32GB VRAM in 5090. Memory bandwidth doesn’t mean a thing if you don’t have enough VRAM. Why do you keep ignoring VRAM? The memory size is everything then. I even shared screenshots of the performance difference between M3 Ultra and 5090.
Regardless of how small or big LLM is as a part of AI ”it’s one of the most advanced and complex applications of AI we currently have.” If Macs can do that you can be sure they can do Deep Learning and Machine Learning too because TensorFlow and PyTorch support macOS too and even then large VRAM is very important. Again you’re shifting focus from your original claims. The question wasn’t about how often Macs are used in different fields of work but if ”M4 series GPUs are not even close to RTX 40 series” or ”Apple can’t even make a high-end GPU”.
While you claimed that Apple GPU isn't sucks and not even close to RTX 40 series, literally none of them proves anything. Is it really hard to compare them with actual games and software, not benchmarks? I said that already.
I didn’t just claim. Everything I posted proves my points and you dodging facts doesn’t change anything. So Blender is not a real 3D software and LLM is not real AI? Don’t you hear how ridiculous that sounds? You still don’t realize that it’s not just about benchmarks. Have you even run Blender benchmark? Monster, Junkshop and Classroom are real 3D scenes that are downloaded to your computer before you can run the benchmark and then rendered. The test is about how fast they can be rendered on different HW so it’s as real as it can get. You can even go to their site and download different demo files for testing and rendering. There is no difference between those demo files and real projects.
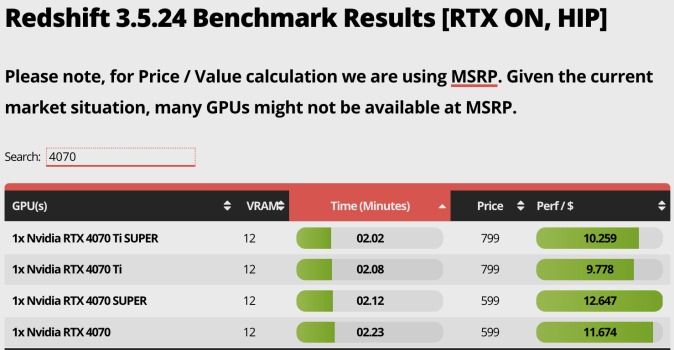
In the Classroom scene M3 Ultra is as fast as desktop 5070 Ti and 4070 Ti Super. M4 Max 40c is faster than desktop 4070 Super, 7900 XTX and 5060 Ti.
In the Lone Monk scene the base M4 Max 32c is faster than desktop 4070 Super and almost as fast as 5070. Now imagine how fast M4 Max 40c or M3 Ultra would be.
In the Barbershop scene M3 Ultra is faster than desktop 5070/4070/3080 Ti and 7900 XTX.
Another 3D software is Maya with Redshift. Can’t find test results for RTX 50 series but M4 Max 40c is as fast as laptop 4090 or desktop 4070/3090 Ti. M3 Ultra is as fast as desktop 4080 which is as fast as 5070 Ti.
Games? You can game on a Mac but everybody knows you don’t buy a Mac primarily for gaming and especially not a M3 Ultra, or 5090 for that matter. The most popular PC GPU on Steam is 3060. Everybody knows that Nvidia is best in gaming and nobody said Mac is good at everything but again your first claims wasn’t about gaming but about ”M4 series GPUs are not even close to RTX 40 series” or ”Apple can’t even make a high-end GPU”.
If you only had said ”Nvidia GPUs are best in gaming” we wouldn’t even have this discussion. AMD and Intel can’t beat Nvidia in games either. It doesn’t mean they ”suck” at gaming and neither do Apple GPUs on their own. M4 Max performs as 4060/4070/4080 M in games. Just for comparison M3 Ultra performs like a desktop 4070 in Death Stranding at 4K Ultra but games almost always run faster on Windows thanks to biffy power-hungry GPUs and better optimization.
Besides, you compared Mac Studio to laptops. Laptop RTX 4090 = desktop RTX 4070 which again proved my point. Apple GPU sucks. Good luck with proving your point with false and misleading info.
You’re the one as usual with ”false and misleading info”. First of all you said ”M4 series GPUs are not even close to RTX 40 series”; That includes both laptop and desktop GPUs. Then you casually compared laptop 4090 to desktop 4070 without any proof while everyone can see that’s not the case in the Blender screenshot I posted. In my first post I said and showed that M3 Ultra is under/close to desktop 5070 Ti and almost as fast. In the Blender test by Mathew Moniz M3 Ultra is almost as fast as ASUS ROG STRIX SCAR18 4090 which is very close to desktop 5070 Ti too, not 4070 like you say. Even so it wouldn’t prove your point because you said ”not even close to RTX 40 series” but laptop 4090 and desktop 4070 belong to 40 series which proves my point.
To say ”what a joke” explains much in this discussion because everything seems to be a joke to you. You didn’t know Blender Render is GPU intensive and said it’s ”CPU intensive software”, you said ”most GPU intensive software dont even support Mac”, you said ”LLM is not even related to GPU intensive software”, you said ”memory size is NOT everything” for LLM, ”LLM is a tiny part of AI”, ”Mac can only do LLM” and ”Ultra series suppose to compete with 90 series according to Apple officially”. None of that is true.
So to recap everything:
- Apple GPUs don’t ”suck” and they can be close, as fast or even above RTX 40/50 series GPUs for laptops and desktops.
- Many ”GPU intensive” software support Mac.
- Blender Render is GPU intensive, not CPU intensive.
- LLMs are totally GPU intensive where VRAM is almost everything and more important than memory bandwidth.
- LLM is not a tiny part of AI, but ”one of the most advanced and complex applications of AI”.
- Maya/Redshift, Blender and LLM are ”actual” real software.
- Apple has never compared M3 Ultra to RTX 5090 or any other card in the 50 series.
You keep making all these claims but later forget or ignore conveniently what your own claims were about. Your main mistake was to say Apple is worst instead of saying Nvidia is best. Nvidia being best in many cases doesn’t make Apple worst. There are worse GPUs, like AMD and Intel and Apple can even be best in some cases like LLM. You may think what you want but facts don’t lie. So next time stop generalizing and using fan fiction instead of facts and try to stay on point instead of moving the goalposts.
Attachments
Last edited by a moderator:
Yet you failed to prove it by showing only LLM as a good example.I see you keep showing your great despise for everything Apple with your ”Apple sucks” and ”What a joke” even in your new posts in other threads. You sure sound a lot like another poster we used to have here. Is that you again sunny5?
No I didn’t fail, but you failed to understand again. I proved exactly what I intended to prove. Your whataboutism and moving the goalposts were never a part of that. Ignoring and denying simple facts just hurts your credibility more each time.
And it is worst. RTX 4070 is max performance that Apple can compare and compete with.You’re literally saying first what I said but still try to make a point of what I didn’t say? This wasn’t a contest about which platform has most users and is irrelevant to the original discussion about your first claims. Everybody knows there are more Windows users in the world or in 3D, AI and gaming, so what? My info was never ”false” because it was neither about ”Mac focused” SW nor about more people choosing Mac rather than PC. This clearly disapproves your pointless argument.
Your claim was ”Mac is worst platform for GPU intensive software where most of them dont even support” and I listed many popular GPU intensive applications that do support Mac, both in 3D, AI and game development. You provided no source for your claim about most of those applications not supporting Mac. I even showed that AMD and Intel GPUs are much worse in Blender Render than Apple’s so that fact also refutes your claim about ”worst platform”.
You’re claiming again falsely that LLM and its related applications are not GPU intensive despite my explanations which shows you’re ignoring the facts again. Below is another screenshot from Alex Ziskind’s channel showing the GPU working at 100%.
It’s quite amusing to see that you check the facts with ChatGPT but still make such false claims. Why don’t you ask ChatGPT ”Is LLM CPU or GPU intensive?” and see which answer you get. I make it easy for you and share the answers below:
- Large Language Models (LLMs) like me (ChatGPT) are GPU-intensive, not CPU-intensive.
- LLMs involve billions of matrix multiplications during both training and inference. These operations are highly parallelizable, which GPUs are optimized for.
- GPUs provide 10×–100× speedups compared to CPUs for LLM workloads.
- GPUs use high-bandwidth VRAM to store model weights and intermediate tensors. If a model doesn’t fit in GPU memory, performance plummets as data is swapped between GPU and CPU memory.
- Training: Extremely GPU-intensive; often uses multiple GPUs or clusters.
- Inference: Still GPU-intensive, though small models can run on CPU if speed isn’t critical.
- LLMs are overwhelmingly GPU-intensive, with CPUs handling orchestration and I/O rather than the math.
The same goes for 3D and game development software. The question wasn’t about the number of users but you claimed most such applications don’t support Mac. I mentioned many popular programs that do support Mac and are used frequently.
Again, LLM is a niche market with TOO specific results just like benchmark. Besides, since it doesn't support ECC, it limits the size of LLM as well. Besides, it's more about the size of memory, not GPU since Mac is using unified memory which is the only advantage.The joke is on you for moving the goalposts all the time when you’re proven wrong, spreading disinformation, ignoring facts/explanations and not even bothering to ask your ChatGPT. Who said that Apple is only good with LLM? Not me; I even shared many Blender results debunking your first claims about ”M4 series GPUs are not even close to RTX 40 series” and ”Apple can’t even make a high-end GPU”. Again you’re the only one making the claim that ”Apple is good only with LLM”.
The discussion wasn’t either about servers, super computers and AI farms and whether Macs can do that so all that is irrelevant and ridiculous. So now you have to compare a Mac with supercomputers to make a point? Of course a Mac ”sucks” compared to a supercomputer. What did you expect? Can RTX 5090 do what a supercomputer does? No!
Who would run local LLMs and why instead of cloud solutions? Maybe you should ask ChatGPT again:
- Privacy & Security: Your data stays local. Nothing you type leaves your machine, which is crucial for sensitive or proprietary information (e.g., legal, medical, business data). No cloud dependency means no risk of data leaks via APIs or third-party servers.
- Offline Access: You can use the model without an internet connection, perfect for air-gapped systems, field work, or locations with poor connectivity.
- Cost Control: Once set up, a local model has no per-token or subscription costs. Great for high-volume use (e.g., generating large text batches, code, or documents).
- Customization & Control: You can fine-tune or prompt-engineer your own model for your domain (legal, medical, creative, etc.). Freedom to modify system prompts, memory, or architecture — things that are locked in cloud models. You can even chain it with other local tools (e.g., embeddings, vector DBs, custom APIs).
- Latency & Speed: Once loaded into memory, responses can be faster than remote APIs (no network delay), especially for smaller models optimized for your hardware.
- Transparency & Experimentation: You can inspect what the model does — weights, tokenization, inference process. Perfect for research, education, and AI development without external restrictions.
So first you complain about me using ”benchmarks” and ask for real-life tests but now you ignore real-life Blender and LLM tests and start to compare GPU specs? Memory bandwidth wasn’t even discussed to begin with. Yes, 5090 is faster when it comes to smaller LMs but I’ve been talking about local LLMs that require far more than 32GB VRAM in 5090. Memory bandwidth doesn’t mean a thing if you don’t have enough VRAM. Why do you keep ignoring VRAM? The memory size is everything then. I even shared screenshots of the performance difference between M3 Ultra and 5090.
Regardless of how small or big LLM is as a part of AI ”it’s one of the most advanced and complex applications of AI we currently have.” If Macs can do that you can be sure they can do Deep Learning and Machine Learning too because TensorFlow and PyTorch support macOS too and even then large VRAM is very important. Again you’re shifting focus from your original claims. The question wasn’t about how often Macs are used in different fields of work but if ”M4 series GPUs are not even close to RTX 40 series” or ”Apple can’t even make a high-end GPU”.
I told you all benchmarks are TOTALLY useless which only test for specific scenes for limited time. It seems you dont even have software to run and test it.I didn’t just claim. Everything I posted proves my points and you dodging facts doesn’t change anything. So Blender is not a real 3D software and LLM is not real AI? Don’t you hear how ridiculous that sounds? You still don’t realize that it’s not just about benchmarks. Have you even run Blender benchmark? Monster, Junkshop and Classroom are real 3D scenes that are downloaded to your computer before you can run the benchmark and then rendered. The test is about how fast they can be rendered on different HW so it’s as real as it can get. You can even go to their site and download different demo files for testing and rendering. There is no difference between those demo files and real projects.
In the Classroom scene M3 Ultra is as fast as desktop 5070 Ti and 4070 Ti Super. M4 Max 40c is faster than desktop 4070 Super, 7900 XTX and 5060 Ti.
Now you are claiming that Apple GPU is not bad since AMD and Intel are not even close to Nvidia? WOW. I never compared AMD and Intel to Nvidia and it was APPLE who compared their chips to Nvidia. Your 4K peek results only proves that M3 Ultra = RTX 4070 which only proves my point: Apple GPU sucks. Dont forget that Ultra series are the best chips that Apple can make while Nvidia has a lot more than RTX 5090 and beyond. Your game tests just proven me right after all.Games? You can game on a Mac but everybody knows you don’t buy a Mac primarily for gaming and especially not a M3 Ultra, or 5090 for that matter. The most popular PC GPU on Steam is 3060. Everybody knows that Nvidia is best in gaming and nobody said Mac is good at everything but again your first claims wasn’t about gaming but about ”M4 series GPUs are not even close to RTX 40 series” or ”Apple can’t even make a high-end GPU”.
If you only had said ”Nvidia GPUs are best in gaming” we wouldn’t even have this discussion. AMD and Intel can’t beat Nvidia in games either. It doesn’t mean they ”suck” at gaming and neither do Apple GPUs on their own. M4 Max performs as 4060/4070/4080 M in games. Just for comparison M3 Ultra performs like a desktop 4070 in Death Stranding at 4K Ultra but games almost always run faster on Windows thanks to biffy power-hungry GPUs and better optimization.
Your claims are biased. Your benchmark screen shots already shows M3 Ultra is as equal as laptop RTX 4090 which is only desktop RTX 4070. Hah, see? My claim stands still.You’re the one as usual with ”false and misleading info”. First of all you said ”M4 series GPUs are not even close to RTX 40 series”; That includes both laptop and desktop GPUs. Then you casually compared laptop 4090 to desktop 4070 without any proof while everyone can see that’s not the case in the Blender screenshot I posted. In my first post I said and showed that M3 Ultra is under/close to desktop 5070 Ti and almost as fast. In the Blender test by Mathew Moniz M3 Ultra is almost as fast as ASUS ROG STRIX SCAR18 4090 which is very close to desktop 5070 Ti too, not 4070 like you say. Even so it wouldn’t prove your point because you said ”not even close to RTX 40 series” but laptop 4090 and desktop 4070 belong to 40 series which proves my point.
It sucks no matter what you say cause it's a fact and you still have NO proofs to support your claim instead of showing false info and biased test results.- Apple GPUs don’t ”suck” and they can be close, as fast or even above RTX 40/50 series GPUs for laptops and desktops.
Support does NOT mean Mac is good for GPU intensive computer and even now, using Mac for GPU intensive software is totally niche compared to Windows.- Many ”GPU intensive” software support Mac.
Wrong, It's more CPU intensive than GPU.- Blender Render is GPU intensive, not CPU intensive.
The truth is unified memory has its limitations due to memory bandwidth.- LLMs are totally GPU intensive where VRAM is almost everything and more important than memory bandwidth.
And yet, you failed to say Mac has GPU intensive software by only using LLM as an example.- LLM is not a tiny part of AI, but ”one of the most advanced and complex applications of AI”.
Benchmarks AREN"T real results.- Maya/Redshift, Blender and LLM are ”actual” real software.
Oh, they did with M1 Ultra to RTX 3090 quite officially which means Ultra series were meant to compete with 90 series which failed terribly. So now you deny the fact that Apple GPU is great?- Apple has never compared M3 Ultra to RTX 5090 or any other card in the 50 series.
Since Apple is going to ditch Mac Pro, how will you gonna say? Their actions also support my claim and RTX 4070's performance is the best that Mac can do? Wow, how surprising.
Why dont you bring this to PC communities and see how it goes? Guess what? I already did and they totally laughed for false info as if Apple GPU is good.
Last edited:
Yet you failed to prove it by showing only LLM as a good example.
And it is worst. RTX 4070 is max performance that Apple can compare and compete with.
Again, LLM is a niche market with TOO specific results just like benchmark. Besides, since it doesn't support ECC, it limits the size of LLM as well. Besides, it's more about the size of memory, not GPU since Mac is using unified memory which is the only advantage.
I told you all benchmarks are TOTALLY useless which only test for specific scenes for limited time. It seems you dont even have software to run and test it.
Now you are claiming that Apple GPU is not bad since AMD and Intel are not even close to Nvidia? WOW. I never compared AMD and Intel to Nvidia and it was APPLE who compared their chips to Nvidia. Your 4K peek results only proves that M3 Ultra = RTX 4070 which only proves my point: Apple GPU sucks. Dont forget that Ultra series are the best chips that Apple can make while Nvidia has a lot more than RTX 5090 and beyond. Your game tests just proven me right after all.
Your claims are biased. Your benchmark screen shots already shows M3 Ultra is as equal as laptop RTX 4090 which is only desktop RTX 4070. Hah, see? My claim stands still.
It sucks no matter what you say cause it's a fact and you still have NO proofs to support your claim instead of showing false info and biased test results.
Support does NOT mean Mac is good for GPU intensive computer and even now, using Mac for GPU intensive software is totally niche compared to Windows.
Wrong, It's more CPU intensive than GPU.
The truth is unified memory has its limitations due to memory bandwidth.
And yet, you failed to say Mac has GPU intensive software by only using LLM as an example.
Benchmarks AREN"T real results.
Oh, they did with M1 Ultra to RTX 3090 quite officially which means Ultra series were meant to compete with 90 series which failed terribly. So now you deny the fact that Apple GPU is great?
Since Apple is going to ditch Mac Pro, how will you gonna say? Their actions also support my claim and RTX 4070's performance is the best that Mac can do? Wow, how surprising.
Why dont you bring this to PC communities and see how it goes? Guess what? I already did and they totally laughed for false info as if Apple GPU is good.
Nope, I debunked all that multiple times with real data and sources while you provided nothing but ”Trust me bro” and your friend ChatGPT which also proved you wrong. You may fool the "PC communities" with your disinformation and made-up claims for a good laugh but you're not fooling anyone here. Enjoy your long vacation.
Register on MacRumors! This sidebar will go away, and you'll see fewer ads.