Got a tip for us?
Let us know
Become a MacRumors Supporter for $50/year with no ads, ability to filter front page stories, and private forums.
Mac Studio With M3 Ultra Runs Massive DeepSeek R1 AI Model Locally
- Thread starter MacRumors
- Start date
- Sort by reaction score
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.

I gotta hand it to Dave Lee
He's made a career on YouTube from playing with gadgets while usually looking like like he just rolled out of bed
😂
I often wonder if he has another job, or if this is his full time gig.
Probably a handful of YouTubers (ie. MKBHD, iJustine) can actually sustain a following and make good money.
Would it be safe to say that in 5-10 years a smartphone will be able to run a model like this internally and without the internet?
Nah.
While early years saw some doublings of the RAM (iPhone 3GS, iPhone 4, iPhone 5, iPhone 6S), those have become rarer, and RAM increases have also become smaller (e.g., from 6 GiB to 8, rather than to 12).
By 2035, maybe we'll have an iPhone with 64 GiB RAM. Almost certainly not 512.
Attachments
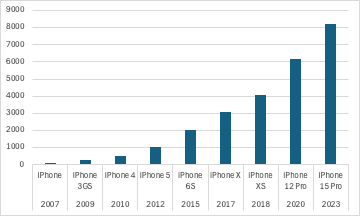
I highly doubt that the typical memory size in a smartphone is going to jump from 8-12gb to 512gb-1tb in the next 5 years, and the only way I even see it in 10 is if we see a move to some kind of optane-like unification of memory and storage, which is unlikelyWould it be safe to say that in 5-10 years a smartphone will be able to run a model like this internally and without the internet?
We are entering a new era of computing where VRAM is becoming increasingly important. Apple's past slow trends in RAM upgrades are not a reliable guide for the future.While early years saw some doublings of the RAM (iPhone 3GS, iPhone 4, iPhone 5, iPhone 6S), those have become rarer, and RAM increases have also become smaller (e.g., from 6 GiB to 8, rather than to 12).
By 2035, maybe we'll have an iPhone with 64 GiB RAM. Almost certainly not 512.
Can somebody explain the actual use of an LLM that cannot search for up-to-date info online?
I'm not being sarcastic, I actually want to know.
Wouldn't the knowledge pool of a local solution be limited by its knowledge at the time of release?
Thanks; I'm really not an expert in this field.
I'm not being sarcastic, I actually want to know.
Wouldn't the knowledge pool of a local solution be limited by its knowledge at the time of release?
Thanks; I'm really not an expert in this field.
Important to note this was a 4-bit quantization. Still impressive. LaurieWired made a good note that the 810 GB/S is actually a bottleneck given models this large, however the MOE architecture would seem to mean that the model can be performant since not all neurons are firing at the same time (or something like that...)
Storage in the Apple Silicon era is getting faster almost annually. We may soon see a unified memory / storage architecture that treats RAM essentially as cache while leaving data in place on the SSD and treating it as it were in RAM.No smartphone will have 512GB of RAM in 10 years. At least not from Apple, if we can go by history. Unless 32GB of iPhone RAM is analogous to 512GB of Mac Studio RAM
Can somebody explain the actual use of an LLM that cannot search for up-to-date info online?
I'm not being sarcastic, I actually want to know.
Wouldn't the knowledge pool of a local solution be limited by its knowledge at the time of release?
Thanks; I'm really not an expert in this field.
Yes it would be limited by knowledge at the time of release, but you might be using it for analysis of offline content, not for searching.
Hold on while I pull out the £15k I’ve got down the back of the sofa…
What pointless article the average person is not going to have that cash to buy one or even want too lol
What pointless article the average person is not going to have that cash to buy one or even want too lol
Not iPhones as they’ll ship with 8GB memory.Would it be safe to say that in 5-10 years a smartphone will be able to run a model like this internally and without the internet?
I do not know how Llama but Deep seek main core is just 32B and rest are other specialized agents loaded into memory as well to be available instantly. That is why 70B model runs slower then this.Probably sooner if you mean equivalent performance, not model size. You can already run Google Gemma 3 27B or Qwen QwQ 34B on a spect out MBP, and they are close to Deepseek in performance.
Just last year Meta’s Llama 3.3 70B matched the performance of Llama 3.1 405B released 6 months prior. X6 efficiency improvement! Llama 3.1 405 was itself close to original GPT4 which had many trillions of parameters. From needing 8 Nvidia h100 to one MBP in two years.
I have no idea how system would perform when models would be loaded into memory as needed.
(speculation) Within 10 years - Reasoning LLM models will slowly optimise to provide:
- rapid responses to the sort of queries that an individual tends to ask (with the necessary data cached in 32GB of VRAM) = equivalent to (humans) Short term memory.
- delayed responses where 128GB of SSD is queried for the vast majority of personalised queries, with libraries of LLM data uploaded in the background depending on the sort of queries are infrequently asked = Long term memory.
- Private Cloud Compute where Larger Models can 'fight it it out' with TB's of memory running on 6G (up to 125GB/s + <1ms latency) in 5 years time (by 2030) = Able to hand off computationally needs (almost) seamlessly.
If Nvidia (and Apple) continue to fund TSMC's leading edge - we will eventually end up with FS (Forksheet FETs) and N/PMOS - with as many layers of memory (cache) that a customer is willing to pay for.
If it takes until 2028 until Siri has redeemed itself and software writers begin in earnest to integrating 'intlligence' into their software (back ends) - then by 2030 we will have Software available across the board (on iOS) that regular users expect to leverage LLMs.
Even if Apple could offer 512GB on the A5 nodes node (2032) onwards - most carriers would already be offering 6G, and so there would not be a competitive reason for Apple to include it in their (foldable) iPhones (or iPads).
I guess, however, that Android phones (one plus) will be offering 128GB RAM phones by 2032 (they are currently at too out at 24GB).
When there is a sweetspot for a personalised reasoning Siri that needs 32GB of VRAM - Apple will make this the base configuration of all new iOS products.... Something tells me the Apple board will ONLY permit this when the Apple engineers have a real (polished) product to release to the masses.
- rapid responses to the sort of queries that an individual tends to ask (with the necessary data cached in 32GB of VRAM) = equivalent to (humans) Short term memory.
- delayed responses where 128GB of SSD is queried for the vast majority of personalised queries, with libraries of LLM data uploaded in the background depending on the sort of queries are infrequently asked = Long term memory.
- Private Cloud Compute where Larger Models can 'fight it it out' with TB's of memory running on 6G (up to 125GB/s + <1ms latency) in 5 years time (by 2030) = Able to hand off computationally needs (almost) seamlessly.
If Nvidia (and Apple) continue to fund TSMC's leading edge - we will eventually end up with FS (Forksheet FETs) and N/PMOS - with as many layers of memory (cache) that a customer is willing to pay for.
If it takes until 2028 until Siri has redeemed itself and software writers begin in earnest to integrating 'intlligence' into their software (back ends) - then by 2030 we will have Software available across the board (on iOS) that regular users expect to leverage LLMs.
Even if Apple could offer 512GB on the A5 nodes node (2032) onwards - most carriers would already be offering 6G, and so there would not be a competitive reason for Apple to include it in their (foldable) iPhones (or iPads).
I guess, however, that Android phones (one plus) will be offering 128GB RAM phones by 2032 (they are currently at too out at 24GB).
When there is a sweetspot for a personalised reasoning Siri that needs 32GB of VRAM - Apple will make this the base configuration of all new iOS products.... Something tells me the Apple board will ONLY permit this when the Apple engineers have a real (polished) product to release to the masses.
And, I think part of the delay of bringing the personal features to the market is due to the changing political climate where certain countries don’t want some personal data (that’s required for things like this to work) to be automatically available to the user. Just saw a law passed in Germany where Google’s Calendar app can’t surface birthdays in contacts. If a user wants to have birthdays, they need to enter them manually. This can add another layer of complexity that wasn’t there before and would need a rethink before it could be offered.With all the crying going on I think Apple is doing this exactly right.
I do like the idea of running models without the cloud. Even if they’re not perfect now, the tech will improve. What’s in the cloud may even ALWAYS be better, but, just like laptops, there will come a time when most everything any average person would need is handled by something mobile.
I wonder how good this thing will do Video Ai stuff. Like Topaz new Starlight or Video Ai work.
I only have the base M3 Ultra Studio version (96gb), but it's noticeably faster running Topaz Video Ai than my previous M1 Ultra or MBP M3 Max or MacMini M4pro (base). I haven't finished playing with it but I have seen TVAI be 10x as fast on the M3 Ultra virus the M4 Pro.. but that is likely to be a factor of RAM as well as GPU's. The fans spin up fast in both cases.
More importantly, can it run Doom?Cool - but how fast can it load MacRumors.com in Safari??? I want real-world cases for myself before I plunk down $15K.
Mobile phones will be less relevant in 10 years let alone running LLM's on optimised hardware. In 10 years devices with screens as primary interfaces might become outdated too. Voice and gestures might be the way forward and a highly optimised and super light vision pro could be part of that future with AI being the main operating system (Something like Jarvis from Iron Man). Would be a good future to look forward to.
Few use-cases for local LLM:
-------------------------------
- Autonomous driving
- Robotic surgery
- Sports analytics
- Personal health management
- Legal system aid for pre-qualification of disputes
- Insurance claims processing
Few use-cases for local LLM:
-------------------------------
- Autonomous driving
- Robotic surgery
- Sports analytics
- Personal health management
- Legal system aid for pre-qualification of disputes
- Insurance claims processing
Last edited:
Unclear. In terms of technology the biggest problem is probably the DRAM.Would it be safe to say that in 5-10 years a smartphone will be able to run a model like this internally and without the internet?
This *might* be doable with HBF (high bandwidth flash) which is one of the buzzwords of 2025 but is not yet a commercial product (and may never be). But even then, that assumes HBF at sufficient performance makes sense in a phone in ten years. Things change fast, yes, but not THAT fast.
But the bigger uncertainty is business model. The privacy hysteria crowd are very vocal on the internet, but their actual purchases tell a different story from their chatter. Plenty of them have Android phones, and most of them are happy to use Google or ChatGPT.
My suspicion is that people will grow up over the next decade as they come to realize the gap between what's feasible and locally and what's feasible via data center. No-one demands that Google Search or Google Maps be available locally (because that would be STUPID) and over time people will, I suspect come to the same realization re the highest end AI. Just like there's some local search, and even downloaded cached maps for special circumstances, some local AI will make sense - but for the top tier stuff, no.
We are entering a new era of computing where VRAM is becoming increasingly important. Apple's past slow trends in RAM upgrades are not a reliable guide for the future.
You expect Apple to increase RAM 64-fold in 11 years? I don’t buy it.
But Apple Silicon 2 will mean 64 GB of RAM will be like 512 GB of Apple Silicon 1 RAMThey can run small models today but it doesn’t seem likely that they’d scale to 512GB of RAM in 10 years.
So 5-10 years from now they will be able to run larger models than the small LLMs we can run today, but no not this sized model.
This is why Chromebook Plus should move to:
core i5 16gb/32gb ram, 512 storage ($300-500) and there should be a new
- Chromebook Pro with core i7 64gb/128gb ram, 1tb storage, 32gb GPU and vram ($500-700) and maybe
Chromebook Max with core i9 256/512gb ram, 2tb storage, 64gb vram, and dedicated GPU ($700-$1000)
core i5 16gb/32gb ram, 512 storage ($300-500) and there should be a new
- Chromebook Pro with core i7 64gb/128gb ram, 1tb storage, 32gb GPU and vram ($500-700) and maybe
Chromebook Max with core i9 256/512gb ram, 2tb storage, 64gb vram, and dedicated GPU ($700-$1000)
We don't quantify it, it just needs to feel snappier!Cool - but how fast can it load MacRumors.com in Safari??? I want real-world cases for myself before I plunk down $15K.
Register on MacRumors! This sidebar will go away, and you'll see fewer ads.