hey, folks:
just took delivery of a 6c nMP and wanted to post a few observations.
i ran geekbench3 with a number of memory configs and figured i would post the results.
the 16GB chips are crucial RDIMMs.
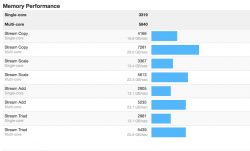
single-core/multi-core:
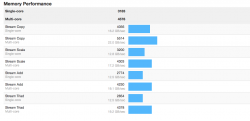
3183/4578 (12GB - 3x4 bank #s 1, 2 & 3)
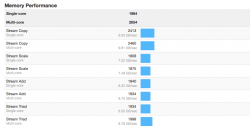
1984/2055 (16GB - 1x16 bank #1)
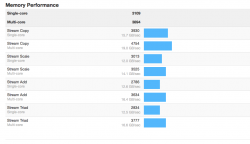
3096/3916 (32GB - 2 banks filled #s 1 & 3)
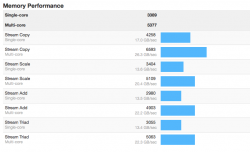
3389/5377 (48GB - 3 banks filled #s 1, 2 & 3)
3319/5840 (64GB - all banks filled)
i found it surprising that 3x4 performed far better (single core) than 1x16. i was also surprised that 4x16 took a hit (albeit slight) in single performance over 3x16.
would be curious if someone with a 4x4 configuration tests 4/8/12 & 16.
just took delivery of a 6c nMP and wanted to post a few observations.
i ran geekbench3 with a number of memory configs and figured i would post the results.
the 16GB chips are crucial RDIMMs.
single-core/multi-core:
3183/4578 (12GB - 3x4 bank #s 1, 2 & 3)
1984/2055 (16GB - 1x16 bank #1)
3096/3916 (32GB - 2 banks filled #s 1 & 3)
3389/5377 (48GB - 3 banks filled #s 1, 2 & 3)
3319/5840 (64GB - all banks filled)
i found it surprising that 3x4 performed far better (single core) than 1x16. i was also surprised that 4x16 took a hit (albeit slight) in single performance over 3x16.
would be curious if someone with a 4x4 configuration tests 4/8/12 & 16.