Apple and Intel have come out to say Mac Pro 2010 and older won't be updated to mitigate CPU bugs like ZombieLoad that are considered exploitable much more easily than Meltdown or Spectre.
A lot of my understanding of this comes from tsialex's postings in MP5,1: BootROM thread | 144.0.0.0.0 with 10.14.5 final
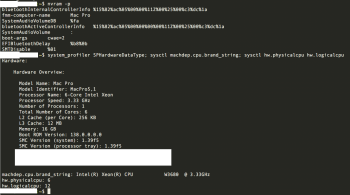
Figured it might be worth asking what people are planning to do about this, since the 2010 and 2009 Mac Pros can still run the latest OS.
A lot of my understanding of this comes from tsialex's postings in MP5,1: BootROM thread | 144.0.0.0.0 with 10.14.5 final
Figured it might be worth asking what people are planning to do about this, since the 2010 and 2009 Mac Pros can still run the latest OS.
Last edited by a moderator: