I've been using a Radeon R9 280X, but I figured I'd give a Titan Black a try.
Using the Nvidia web drivers, everything is running fine in 10.9.4.
I tried running a couple of benchmarks, and so far I get worse numbers than my Radeon got. Luxmark (Sala): 2400 vs 1800. Cinebench OpenGL: 64 vs 53.
So I'm now wondering if I am missing something ---- exactly where would the Titan Black excel? I know the extra VRAM is great in some applications, but what is there beyond that?
I'm not looking to put down the Titan, but I want to know where it would be better for me (while I still have a return window on the Titan)....
Cinebench, as packaged, doesn't measure what the Titan (Black or original) does best and that is CUDA rendering. Currently, there is no CPU that can match a GPU in rendering because that task relies mainly on parallelism. I've estimated that the Titan Black is 1.34x faster than the original Titan [see footnote below]. I have, e.g., tied the Cinebench scene file into my CUDA chain and rendered it in Cinema 4d using Octane and other CUDA based renderers such as TheaRender.
*/ I don't doubt that AMD cards have superior compute capability. I have a Hackie system with three PowerColor Radeon HD 5970s [each card has single precision FPP performance of 4,640 GFLOPS (13,920 GFLOPS total) and double precision FPP performance of 928 GFLOPS (2,784 GFLOPS total)] and at OpenCL tasks it's very fast. The rub is that there aren't that many content creation applications that I use that can tap OpenCL for rendering. On the other hand, there are many more content creation apps that I use that take advantage of CUDA [See, e.g.,
http://www.nvidia.com/content/PDF/gpu-accelerated-applications.pdf ]. That's why I have over 65 CUDA cards.
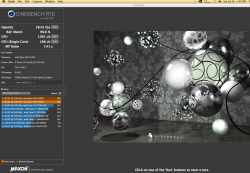
*/ The CUDArized Cinebench 15 performance of one of my 2007 MacPro2,1s is shown in the pict below. Note the CUDA card that I used has modest CUDA performance (I had in my system, at that time, 4x GT640s overclocked about 20%). Yet, the GPU Cinebench scores are close to the CPU scores of current high end Mac Pros. According to Nvidia, the original Titan [actually they used the Tesla K20 in the statement, but the original Titan renders faster than the K20 because of the Titan's greater clock speeds] has the compute performance of up to 10 computer systems each with a single E5-2687W v1 [
http://www.nvidia.com/content/tesla/pdf/NVIDIA-Tesla-Kepler-Family-Datasheet.pdf ]. Here's how CUDA cards that I've own and have tested stack up in relation to the original Titan -
GPU Performance Review
I. My CUDA GPUs’ Titan Equivalency*/ (TE) from highest to lowest (fastest OctaneRender**/ Benchmark V1.20 score to lowest):
1) EVGA GTX 780 Ti Superclock (SC) ACX / 3gig (G) = TE of 1.319 (The current Titan Black should perform a little better since it has slightly higher base, boost and memory speeds, but unfortunately for me I don’t own one, so I can’t test it);
2) EVGA GTX 690 / 4G = TE of 1.202;
3) EVGA GTX Titan SC / 6G = TE of 1.185;
4) EVGA GTX 590C = TE of 1.13;
The original Reference Design (oRD) Titan that Bare Feats tested = TE of 1.0 (95 secs);
5) EVGA GTX 480 SC / 1.5G = TE of .613;
6) EVGA GTX 580 Classified (C) / 3G = TE of .594; and
7) Galaxy 680 / 4G = TE of .593.
Estimating TE Differential of GTX 780 Ti vs. GTX Titan Black
I. Factors considered are:
1) Pixel (GP/s) differential */: 42.7 (GTX Titan Black) / 42 (GTX 780 Ti) = 1.01666666666667
2) (a) Core count, (b) memory speed (MHz) and (c) bandwidth are the same on both GPUs
3) Base clock rate differential: 889 (GTX Titan Black) / 875 (GTX 780 Ti) = 1.016
II. TE of EVGA GTX 780 Ti Superclock (SC) ACX / 3gig (G) = 1.319
1.319 (780 Ti TE) * 1.016 (Titan Black important differentials) = 1.340104
95 (time in secs taken by oRD Titan to render 1.20 Benchmark scene) / 1.340104 = 70.89002047602276 secs (estimate of time in secs one Titan Black will take to render 1.20 Benchmark scene); therefore,
two Titan Blacks should render the scene in ~ 35 to 36 secs. Also, one Titan Black would be expected to have a TE of 1.34 (1.340104 rounded) and two Titan Blacks would be expected to have a TE of 2.68 (1.34 * 2 = 2.68). Accordingly, it appears that it would take 2.68 of the original reference design Titans to yield the same rendering performance of two Titan Blacks. **/
*/ Info source:
http://en.wikipedia.org/wiki/List_of_Nv ... sing_units
**/ In Windows, one can use EGVA Precision X to affect how a GTX GPU performs Octane renders. The most important parameter is the memory speed, secondly is the core and thirdly is the boost clock. Don’t mess with the voltage until you’re a tightrope walker. Remember that when tweaking, less is more. So tweak relevant values in baby steps and test render the Octane benchmark scene at least five times (noting the render time changes and especially system stability) between each stride (subsequent change in memory or core or boost clock) and always keep those temps as low as possible. If your GPU(s) already run(s) hot, then use Precision X to underclock these same parameters. But remember, you’re always tweaking solely at your own peril.