adamw
macrumors 6502a
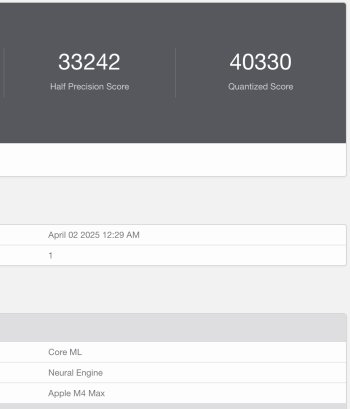
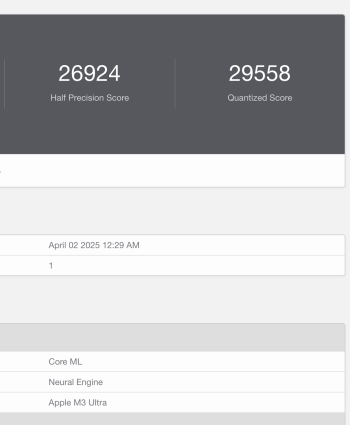
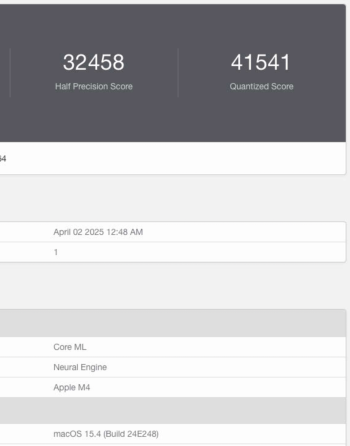
Many people are dumping their M1 Max and M1 Ultra Mac Studio models, just look on FB Marketplace or eBay to see so many for sale currently. The price has sure dropped also. You may want to keep yours, or sell it and upgrade to a M4 Max or M3 Ultra Mac Studio model, while you can still get a decent price for yours. I have a feeling the M1 Max and M1 Ultra Mac Studio models will soon become dinosaurs and not command that much of a price.I've had my M1 Max Mac Studio since day one, and so far it's been excellent. It's done everything I've asked without batting an eye and has been super silent doing it. I'll keep it until I start seeing a need to upgrade, but I don't see that happening for at least 3 more years.