Got a tip for us?
Let us know
Become a MacRumors Supporter for $50/year with no ads, ability to filter front page stories, and private forums.
So is anyone actually running a GTX 1070/80?
- Thread starter Messy
- Start date
- Sort by reaction score
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
flowrider
macrumors 604
Short answer - NO DRIVER'S YET! Check out this thread:
https://forums.macrumors.com/threads/nvidia-gtx-1080.1971528/
Lou
https://forums.macrumors.com/threads/nvidia-gtx-1080.1971528/
Lou
AidenShaw
macrumors P6
Your "short answer" is to a different question.Short answer - NO DRIVER'S YET! Check out this thread:
https://forums.macrumors.com/threads/nvidia-gtx-1080.1971528/
Lou
The question is "are Pascal GTX cards shipping and delivered". Clearly they are, and people running Linux and Windows are using them already - sometimes even in a cMP.
You shouted an answer to the question "are there Apple OSX drivers for Pascal GTX cards".
I wonder if Tim Cook's equivalents at Nvidia (you know, the bean counters) have run the numbers on the pros and cons of creating Pascal drivers for Apple OSX.
The "pro" would be that for a modest cost Nvidia could help MVC sell some cards to cMP users.
The "con" would be that dropping Apple OSX support might tip more people into realizing that Apple is abandoning higher performance systems for iToys with big screens. Those people might leave the Apple ecosystem (and the "Objective-C/OpenGL/OpenCL/Metal/Vulkan/Swift/whatever-the-API-of-the-week-is" ecosystem) and jump to the CUDA ecosystem.
Not much of a "pro", and a pretty convincing "con".
[doublepost=1468023518][/doublepost]
I thought of another "pro". If the cMPs with Pascal GPUs continue to destroy the MP6,1 on compute benchmarks, maybe Apple will be shamed into offering an Nvidia option on the MP7,1....
I wonder if Tim Cook's equivalents at Nvidia (you know, the bean counters) have run the numbers on the pros and cons of creating Pascal drivers for Apple OSX.
The "pro" would be that for a modest cost Nvidia could help MVC sell some cards to cMP users.
The "con" would be that dropping Apple OSX support might tip more people into realizing that Apple is abandoning higher performance systems for iToys with big screens. Those people might leave the Apple ecosystem (and the "Objective-C/OpenGL/OpenCL/Metal/Vulkan/Swift/whatever-the-API-of-the-week-is" ecosystem) and jump to the CUDA ecosystem.
Not much of a "pro", and a pretty convincing "con".
Last edited:

SoyCapitanSoyCapitan
Suspended
Your "short answer" is to a different question.
If the cMPs with Pascal GPUs continue to destroy the MP6,1 on compute benchmarks, maybe Apple will be shamed into offering an Nvidia option on the MP7,1.
As we know, performance per watt and per clock the Fiji beats Pascal at most of the OpenCL operations that Apple and Adobe care about. If it's about CUDA rendering then just attach a dedicated rendering system or farm to the workflow.
If we get Pascal it will be in MacBook Pro and midrange iMac.
As we know, performance per watt and per clock the Fiji beats Pascal at most of the OpenCL operations that Apple and Adobe care about. If it's about CUDA rendering then just attach a dedicated rendering system or farm to the workflow.
If we get Pascal it will be in MacBook Pro and midrange iMac.
Perf per watt per clock is not a meaningful metric. Perf per watt absolutely is, and Pascal continues the trend of NVIDIA being miles ahead of AMD on that front.
koyoot
macrumors 603
1920 CC's x2 x 1.693 GHz /154W = 43,3 GFLOPs/watt.Perf per watt per clock is not a meaningful metric. Perf per watt absolutely is, and Pascal continues the trend of NVIDIA being miles ahead of AMD on that front.
2304 GCNC x2 x 1.266 GHz/164W = 35.6 GFLOPs/watt.
4096 GCN cores x 2 x 0.89GHz/184W = 39.6 GFLOPs/watt.
It is ahead but not by miles.
SoyCapitanSoyCapitan
Suspended
Perf per watt per clock is not a meaningful metric. Perf per watt absolutely is, and Pascal continues the trend of NVIDIA being miles ahead of AMD on that front.
Ah yeah....another one of your amazing evidence based opinions on this forum.
The 1080 loses badly in OpenCL against Fiji based chips including the power efficient Nano despite the fact that the Radeon cards are running at almost half the clockspeed.
Laters
Attachments
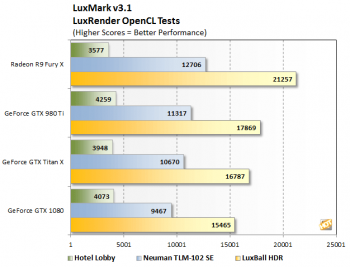
The 1080 loses badly in OpenCL against Fiji based chips including the power efficient Nano when running specific OpenCL kernels that are a good match for the GCN architecture despite the fact that the Radeon cards are running at almost half the clockspeed.
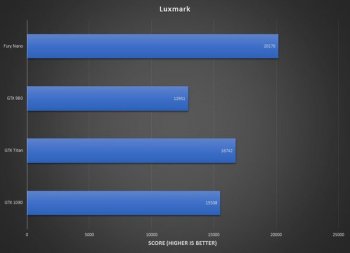
Fixed that for you. Clock speed has nothing to do with it, I'm not sure why you keep bringing it up as something that is bad for NVIDIA (why wasn't AMD able to raise their clocks more when moving to a new process?). Attaching other OpenCL results that contradict yours, since I can cherry-pick results too.
Attachments
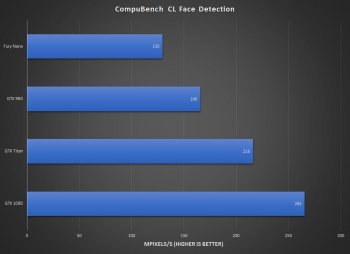
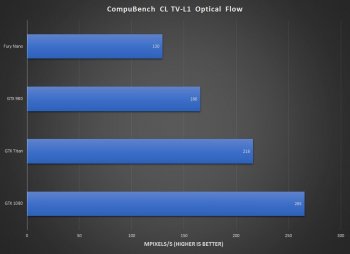
koyoot
macrumors 603
You do not understand what Luxmark does and what does CompuBench with Optical Flow and FaceDetection?Fixed that for you. Clock speed has nothing to do with it, I'm not sure why you keep bringing it up as something that is bad for NVIDIA (why wasn't AMD able to raise their clocks more when moving to a new process?). Attaching other OpenCL results that contradict yours, since I can cherry-pick results too.
Luxmark is benchmark for rendering in OpenCL, Optical Flow and Face Detection are Image Analysis benchmarks.
P.S. You forgot to include Ocean Surface benchmarks in which AMD is also scoring better than Nvidia. And guess what type of Benchmark is it? Compute rendering!
Two different things. Nvidia is better at one thing AMD is better at second. You choose which is better for your needs.
Just because OpenCL is used for benchmarks does not mean everything you need to know.
P.S.2. None of you see that GTX 1080 is slower than Titan X in compute rendering? IF you will look at architecture and size of Registry file size, and caches for each SM's both in Maxwell and Pascal you will know why is that.
Last edited:
You do not understand what Luxmark does and what does CompuBench with Optical Flow and FaceDetection does?
Luxmark is benchmark for rendering in OpenCL, Optical Flow and Face Detection are Image Analysis benchmarks.
Two different things. Nvidia is better at one thing AMD is better at second. You choose which is better for your needs.
Just because OpenCL is used for benchmarks does not mean everything you need to know.
P.S. None of you see that GTX 1080 is slower than Titan X in compute rendering?
Luxmark is a ray-tracing benchmark that uses a particular algorithm that suits GCN more than the NVIDIA architectures. Those two CompuBench tests use OpenCL algorithms that suit the NVIDIA architecture more than GCN. That's the whole point I've been trying to make to you guys for months now. You can tune an OpenCL kernel so that it will work very well on one architecture (or even one specific GPU) at the expense of running poorly on other architectures or GPUs. There is no such thing as an OpenCL kernel that runs optimally on every single GPU from every single vendor.
A reasonable conclusion to draw is this: GCN runs Luxmark well, so if all I need is to run Luxmark or LuxRender, then I should buy a GCN GPU. Same applies to any one specific benchmark, if that's all you care about then by all means buy the GPU that runs that one benchmark or application the best.
An unreasonable conclusion to draw is this: GCN runs Luxmark well, so it's a superior compute architecture in all cases to Pascal.
There are plenty of CUDA-based ray tracing solutions that perform better than Luxmark on NVIDIA GPUs, probably because they've been tuned to run well on NVIDIA GPUs by definition.
koyoot
macrumors 603
Proofs. Not your logic based on encyclopaedia of optimising compute algorithms for GCN or CUDA architectures.Luxmark is a ray-tracing benchmark that uses a particular algorithm that suits GCN more than the NVIDIA architectures. Those two CompuBench tests use OpenCL algorithms that suit the NVIDIA architecture more than GCN. That's the whole point I've been trying to make to you guys for months now. You can tune an OpenCL kernel so that it will work very well on one architecture (or even one specific GPU) at the expense of running poorly on other architectures or GPUs. There is no such thing as an OpenCL kernel that runs optimally on every single GPU from every single vendor.
A reasonable conclusion to draw is this: GCN runs Luxmark well, so if all I need is to run Luxmark or LuxRender, then I should buy a GCN GPU. Same applies to any one specific benchmark, if that's all you care about then by all means buy the GPU that runs that one benchmark or application the best.
An unreasonable conclusion to draw is this: GCN runs Luxmark well, so it's a superior compute architecture in all cases to Pascal.
There are plenty of CUDA-based ray tracing solutions that perform better than Luxmark on NVIDIA GPUs, probably because they've been tuned to run well on NVIDIA GPUs by definition.
Luxmark 2.0 was better optimised for Nvidia hardware. Later Luxmark renderer went for streamlined benchmark that would be brand agnostic.
All comptue benchmarks should be non-biased for architectures. At least in todays world.
Proofs. Not your logic based on encyclopaedia of optimising compute algorithms for GCN or CUDA architectures.
Luxmark 2.0 was better optimised for Nvidia hardware. Later Luxmark renderer went for streamlined benchmark that would be brand agnostic.
All comptue benchmarks should be non-biased for architectures. At least in todays world.
What more proof do you need, aside from the massive lead GCN has in Luxmark versus the massive lead the NVIDIA GPUs have in the CompuBench tests I attached above? I'm not even suggesting that the benchmark authors are going out of their way to make their tests favour one GPU or architecture over the others, it's just really hard to write something that runs efficiently on all GPUs. Have you written and tuned the performance of OpenCL code?
Again, all I'm saying is that you can't reasonably claim that GCN is a better compute architecture in all cases. Period. Nothing more, nothing less. There are plenty of examples, both with OpenCL and CUDA, where NVIDIA performs extremely well.
SoyCapitanSoyCapitan
Suspended
OpenCL is all that matters if we are taking about Apple.
The Optical Flow, Face Detection, etc benchmarks mean nothing to the macOS platform, Final Cut, Creative Suite and the APIs that Mac developers code for.
The Optical Flow, Face Detection, etc benchmarks mean nothing to the macOS platform, Final Cut, Creative Suite and the APIs that Mac developers code for.
OpenCL is all that matters if we are taking about Apple.
The Optical Flow, Face Detection, etc benchmarks mean nothing to the macOS platform, Final Cut, Creative Suite and the APIs that Mac developers code for.
Actually, I'd argue that Metal is all that matters going forward, but sure.
Per my post above, if all you care about is running Final Cut Pro or the Adobe Creative Suite on macOS, and you find that GCN products perform the best at those benchmarks, then you obviously should buy a GCN GPU or an Apple system that features a GCN GPU such as the 2013 Mac Pro. If GCN performs better at those specific applications then by all means you should stick with GCN if you use those applications.
koyoot
macrumors 603
Because both are different jobs.What more proof do you need, aside from the massive lead GCN has in Luxmark versus the massive lead the NVIDIA GPUs have in the CompuBench tests I attached above? I'm not even suggesting that the benchmark authors are going out of their way to make their tests favour one GPU or architecture over the others, it's just really hard to write something that runs efficiently on all GPUs. Have you written and tuned the performance of OpenCL code?
Again, all I'm saying is that you can't reasonably claim that GCN is a better compute architecture in all cases. Period. Nothing more, nothing less. There are plenty of examples, both with OpenCL and CUDA, where NVIDIA performs extremely well.
It is like comparing Game to working on huge data. One benchmark is compute rendering - ray-tracing benchmark, second is simply Image Analysis. You see the difference?
Yes, you can write something that runs efficiently on all GPUs. By not adding specific things for each architecture.
That is because AMD architecture is better at using compute for rendering...Actually, I'd argue that Metal is all that matters going forward, but sure.
Per my post above, if all you care about is running Final Cut Pro or the Adobe Creative Suite on macOS, and you find that GCN products perform the best at those benchmarks, then you obviously should buy a GCN GPU or an Apple system that features a GCN GPU such as the 2013 Mac Pro. If GCN performs better at those specific applications then by all means you should stick with GCN if you use those applications.
What other proof you want here, than how FCPX performs on both brands?
That is because AMD architecture is better at using compute for rendering...
There you go again, making definitive statements that are simply not true.
http://furryball.aaa-studio.eu/aboutFurryBall/benchmarks.html
http://furryball.aaa-studio.eu/support/benchmark.html
There's some examples of a GPU compute ray tracer running on NVIDIA. You can't say "GCN is better at ray tracing" and cite Luxmark as proof. You can say "GCN runs Luxmark better than NVIDIA and thus if you care most about Luxmark/LuxRender performance you should go and buy a GCN GPU". Do you not understand the difference?
Edit: NVIDIA even has a ray-tracing product that is specifically tuned for their GPUs:
https://developer.nvidia.com/optix
koyoot
macrumors 603
May I ask, why you compare proprietary closed ecosystem of API versus open, Multiplatform API?
AMD is better at Compute rendering in OpenCL. Is that better for you? CUDA is without question here, because it is only for Nvidia, and Nvidia themselves product.
At last we are home. Only thing you get on Apple platform is either OpenCL or Metal. Why even putting here CUDA?
P.S. AMD is better in compute rendering in open, Multiplatform benchmark. Nvidia is better at closed, proprietary benchmark, that is not available for AMD. You see the difference now?
AMD is better at Compute rendering in OpenCL. Is that better for you? CUDA is without question here, because it is only for Nvidia, and Nvidia themselves product.
At last we are home. Only thing you get on Apple platform is either OpenCL or Metal. Why even putting here CUDA?
P.S. AMD is better in compute rendering in open, Multiplatform benchmark. Nvidia is better at closed, proprietary benchmark, that is not available for AMD. You see the difference now?
Last edited:
May I ask, why you compare proprietary closed ecosystem of API versus open, Multiplatform API?
AMD is better at Compute rendering in OpenCL. Is that better for you? CUDA is without question here, because it is only for Nvidia, and Nvidia themselves product.
At last we are home. Only thing you get on Apple platform is either OpenCL or Metal. Why even putting here CUDA?
CUDA absolutely runs on macOS, and lots of people use multiple big NVIDIA GPUs in external PCIe enclosures (e.g. Cubix Xpander) for CUDA applications.
The only thing I'm objecting to is you guys making generic conclusions based on one benchmark like Luxmark. AMD is better at Luxmark than NVIDIA is, no argument there.
koyoot
macrumors 603
If your benchmark is Multiplatform, and open, and uses open standards it has to be taken that way.CUDA absolutely runs on macOS, and lots of people use multiple big NVIDIA GPUs in external PCIe enclosures (e.g. Cubix Xpander) for CUDA applications.
The only thing I'm objecting to is you guys making generic conclusions based on one benchmark like Luxmark. AMD is better at Luxmark than NVIDIA is, no argument there.
If your benchmark is based on proprietary, locked standard it has to be taken differently.
AMD is better at GPU rendering in open, multiplatform benchmark. This is only benchmark that allows comparing performance of GPUs from different brands, with using open standards.
That is why people take conclusions from open, Multiplatform benchmarks, about compute capabilities of GPUs from different brands. The same thing happens when people compare GPU rendering using OpenCL in... Final Cut Pro X. That AMD has better performance here compared to Nvidia GPUs, of the same level of compute performance.
It is hard to explain to anyone this simpler.
h9826790
macrumors P6
Perf per watt absolutely is, and Pascal continues the trend of NVIDIA being miles ahead of AMD on that front.
It looks like you are the person who initiate to say that Nvidia continues being miles ahead of AMD in perf per watt. Therefore, they just pick some proof to disagree your point of view.
And then you change the subject and say that they intentionally pick the benchmark that works better for AMD? Of course they did, because they want to proof that Nvidia is not always better in perf per watt.
I think from the above discussions. It's clear that Nvidia not always win, same as AMD, they are stronger in different areas. Or even may be actually not the GPU is stronger, but just the driver is better written, or the programmer optimise the software to make it works better on one GPU then the others.
If Nvidia can always do better, then it has to be for every single software, benchmark, operation...
I don't want to join the war about red vs green. I don't have enough knowledge to join the debate either. But just want to point out that your initial statement (which start the debate) about Nvidia absolutely doing better in perf per watt is not necessary correct (even though we take out the "miles ahead")
SoyCapitanSoyCapitan
Suspended
Basically some few people (who are sometimes forum salesmen for Nvidia resellers) forget...
Apple wants strong OpenCL rendering performance.
Nvidia wants developers to work with CUDA and so they cripple OpenCL performance.
AMD has strong OpenCL performance and wants more open standards to challenge CUDA.
Apple wants strong OpenCL rendering performance.
Nvidia wants developers to work with CUDA and so they cripple OpenCL performance.
AMD has strong OpenCL performance and wants more open standards to challenge CUDA.