If you are looking for MSRP, unless you are trolling for FE cards from BB (assuming US) that ship has sailed. You can get a 3090 right now on Newegg for $3K…That is ridiculous! I am looking for a 3080 or 3090. I am not sure when I will be able to get an NVIDIA card again.
Got a tip for us?
Let us know
Become a MacRumors Supporter for $50/year with no ads, ability to filter front page stories, and private forums.
Intel Says New Core i9 Processor for Laptops is Faster Than Apple's M1 Max Chip
- Thread starter MacRumors
- Start date
- Sort by reaction score
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
You can buy pre-built PCs from CyberPower, iBuyPower and others that have those graphics cards and not pay the scalper surcharge.That is ridiculous! I am looking for a 3080 or 3090. I am not sure when I will be able to get an NVIDIA card again.
For example here’s one with a 3060 card for $1,494

CYBERPOWERPC Gamer Xtreme VR Gaming PC, Intel Core i5-11600KF 3.9GHz, 16GB DDR4, GeForce RTX 3060 12GB, 500GB NVMe SSD, 1TB HDD, WiFi Ready & Win 11 Home (GXiVR8480A10)
Destroy the competition with the CYBERPOWERPC Gamer Xtreme VR series of gaming desktops. The Gamer Xtreme VR series features the latest generation of high performance Intel Core processors and ultra-quick DDR RAM to easily handle system-intensive tasks, such as high definition video playback and ...
www.amazon.com
As an Amazon Associate, MacRumors earns a commission from qualifying purchases made through links in this post.
I used to look every single day for one, I gave up a couple months ago. I guess in a few months I will just look at getting a custom built PC and taking the GPU out. At least I will have some other stuff for the $2K or $3K cost. Even though I stopped buying pre-builts a long time ago because I found them to be pure garbage.If you are looking for MSRP, unless you are trolling for FE cards from BB (assuming US) that ship has sailed. You can get a 3090 right now on Newegg for $3K…
I really don't like the idea of pre-builts since I have used them before and they are just pure garbage. Maybe things have changed, but they were NOT good back then.You can buy pre-built PCs from CyberPower, iBuyPower and others that have those graphics cards and not pay the scalper surcharge.
For example here’s one with a 3060 card for $1,494
CYBERPOWERPC Gamer Xtreme VR Gaming PC, Intel Core i5-11600KF 3.9GHz, 16GB DDR4, GeForce RTX 3060 12GB, 500GB NVMe SSD, 1TB HDD, WiFi Ready & Win 11 Home (GXiVR8480A10)
Destroy the competition with the CYBERPOWERPC Gamer Xtreme VR series of gaming desktops. The Gamer Xtreme VR series features the latest generation of high performance Intel Core processors and ultra-quick DDR RAM to easily handle system-intensive tasks, such as high definition video playback and ...www.amazon.com
As an Amazon Associate, MacRumors earns a commission from qualifying purchases made through links in this post.
Not much, I think. Some people just REALLY love the challenge of building something new and then, after having built it, goes somewhere else to build something else new. It’s the same as the car thing. When you hear that the person that designed the battery is moving on, that’s not a bad thing. They LIKE designing batteries and this one is done, on to the next challenge!Apple lost their Apple Silicon lead to Intel. Wonder how much of impact that will have for either company. Nice career move from Principle Engineer to Director then CTO.
https://appleinsider.com/articles/2...d-apple-silicon-designer-jeff-wilcox-to-intel
So, I’d never thought about that before as I figured everyone would use similar quality parts, BUT they’re likely just going with whatever’s cheapest this quarter, huh? And, in these days where they recognize folks are buying complete builds in order to take out the GPU, it might even be that they’re including even CHEAPER parts to maximize the profits. I mean, maybe not, but certainly not in the realm of impossibility.I really don't like the idea of pre-builts since I have used them before and they are just pure garbage. Maybe things have changed, but they were NOT good back then.
I seriously regret not getting the RTX 2080 before the 30 series launched. I thought "30 series is coming out in a few months, I will wait". Biggest mistake ever as the 20 series cards were readily available at the time at reasonable prices.So, I’d never thought about that before as I figured everyone would use similar quality parts, BUT they’re likely just going with whatever’s cheapest this quarter, huh? And, in these days where they recognize folks are buying complete builds in order to take out the GPU, it might even be that they’re including even CHEAPER parts to maximize the profits. I mean, maybe not, but certainly not in the realm of impossibility.
Exactly what's in my PC, too. Got it in 2019 also (or 2018).I'm glad I bought an RTX 2070 way back in 2019.
That was before the scalpers got ahold of the market.
🤣
a i9 wouldn't come in a base model laptop or PC though.
You can get a M1 in a Mac Air.
Or a Mini.
Intel blindly chasing speed to try to drive sales rather than taking care of any of the actual issues in their processors, like the fact they're still including a sysadmin diagnostic tool in gaming PC processors you can't disable or else it bricks your processor or that they're still on 10nm and don't have any claims to security to counterbalance it, reminds me of the Pentium 4 -- except this time anyone calling them out on the former are all labelled conspiracy theorists.
Also, an i9? Really? Let's hope they reintroduce the Lombard form factor, that dual battery setup is gonna be necessary.
Intel blindly chasing speed to try to drive sales rather than taking care of any of the actual issues in their processors, like the fact they're still including a sysadmin diagnostic tool in gaming PC processors you can't disable or else it bricks your processor or that they're still on 10nm and don't have any claims to security to counterbalance it, reminds me of the Pentium 4 -- except this time anyone calling them out on the former are all labelled conspiracy theorists.
Also, an i9? Really? Let's hope they reintroduce the Lombard form factor, that dual battery setup is gonna be necessary.
Hey RigbyThey used the Apple's Xcode compiler for the M1 and Intel's ICC compiler for the Alder Lake. How is that "shenanigans"? And just in case you didn't now, LLVM is not a compiler but a compiler framework (and, BTW, ICC also uses LLVM now). Apple has every opportunity to optimize the Xcode compiler (and particularly their back end for the M1), so it's only fair that Intel is given the same opportunity.
")
I was aware (already) that both Intels latest ICC and Apples shipped XCode are based on the LLVM compiler and toolchain frameworks - I do appreciate that you checked that I understood that. In this day and age on the internet it’s really important that we are all on the same page
However, from the tone of your response to me, I get a sense that very detailed specificity is important to you - and I hope that in the spirit of seeking that specificity, you won’t be insulted when I share that you are wrong in the assertion that “LLVM is not a compiler” !
From the LLVM project (highlighted screenshot also provided below for your consideration:
The LLVM Project is a collection of modular and reusable compiler and toolchain technologies. Despite its name, LLVM has little to do with traditional virtual machines. The name "LLVM" itself is not an acronym; it is the full name of the project.
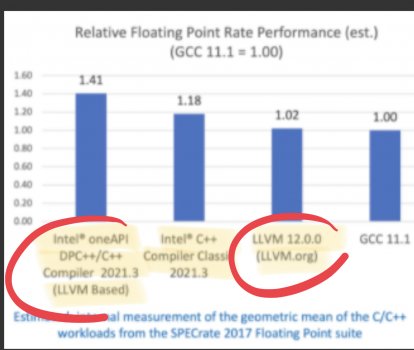
I mentioned Intel’s LLVM backed ICC (and referenced it to ICC) because the version that Intel ships does not generate similar binary output to opensource CLang LLVM projects. Intel even mentions that their version of the LLVM backed ICC includes optimizations and enhancements that do not make their way upstream to the LLVM project itself (again see screenshots below).
Please do not take my word for it, please have a read of Intels’ own language on this very matter…
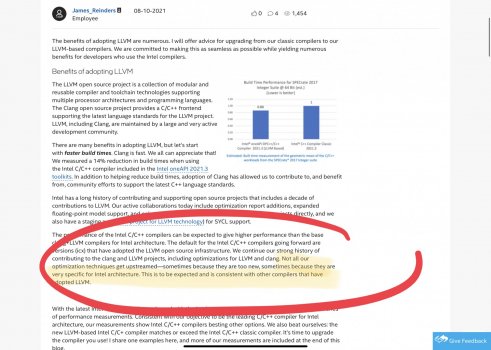
Intel C/C++ compilers complete adoption of LLVM
The benefits of adopting LLVM are numerous. I will offer advice for upgrading from our classic compilers to our LLVM-based compilers. We are committed to making this as seamless as possible while yielding numerous benefits for developers who use the Intel compilers. Benefits of adopting LLVM...
community.intel.com
I’ve attached and highlighted interesting commentary from Intel themselves on this very matter (as well as screencaps of benchmark differences that Intel advertises as it relates to ICC on Spec tests in comparison with open source CLang-LLVM generated binaries (again here, it’s hard to compare because of default behavior of ICC and open source projects
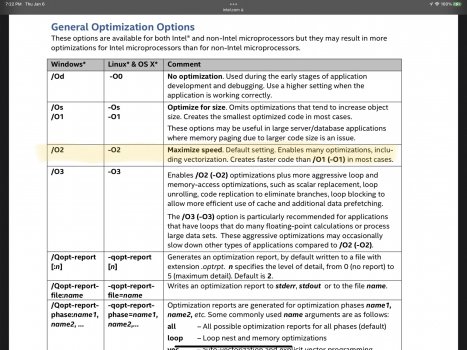
even on Intel!).For the purpose of the discussion here, the Intel C Compiler defaults to -O2 with autovectorization, loop unrolling etc…
(see again the attached documentation screenshots for your interest on ICC and default optimization levels) - default is -O2 or FAST.
This level of optimization in ICC would be the equivalent of an XCode project being explicitly run with -O3 for autovectorization, loop unrolling etc…
The default projects in XCode are -debug (for fast recompilation, debug etc…) and -release (this trades smaller binary file sizes for release).
Why I am sharing this?
Without much more information provided by Intel and beyond what we already know are the significant differences in default optimization level philosophy by Intel and Apple - it is VERY hard to truly say know whether we are seeing a test where every effort was made to make the test as apples:apples or not. I’m looking forward to independent third parties to disect and reproduce (as I was also anxiously awaiting anandtechs breakdown of M1 Max on release).
Most importantly to what I am interested in these days - I’ll anxiously await a benchmark where laptop alderlake exports an H.265 40% faster than M1 Max or compiles a large .NET Core or Angular project faster than M1 Max …. while on battery ….
Hope some of what I shared here was helpful or at least makes for an interesting conversation talking point
Have a really great day.
Attachments
-
 DD750D0C-D567-4754-9966-E295925A8B47.jpeg623.1 KB · Views: 84
DD750D0C-D567-4754-9966-E295925A8B47.jpeg623.1 KB · Views: 84 -
 56842A40-D817-4CAB-AFF9-78FFB4F8D64A.jpeg624.6 KB · Views: 73
56842A40-D817-4CAB-AFF9-78FFB4F8D64A.jpeg624.6 KB · Views: 73 -
 7F4B4037-A451-4D75-93A8-66EDD7F76B69.jpeg76.6 KB · Views: 89
7F4B4037-A451-4D75-93A8-66EDD7F76B69.jpeg76.6 KB · Views: 89 -
 CFB9AEAC-9897-40C1-B601-7231D59325E3.jpeg364.4 KB · Views: 76
CFB9AEAC-9897-40C1-B601-7231D59325E3.jpeg364.4 KB · Views: 76 -
 FA9AC104-FA06-4ADF-B708-596FBC22A57A.jpeg438 KB · Views: 78
FA9AC104-FA06-4ADF-B708-596FBC22A57A.jpeg438 KB · Views: 78
But nonetheless you are ready to call "shenanigans" ...Without much more information provided by Intel and beyond what we already know are the significant differences in default optimization level philosophy by Intel and Apple - it is VERY hard to truly say know whether we are seeing a test where every effort was made to make the test as apples:apples or not.
I wonder if you also spent so much effort to speculate about compiler flags and other "shenanigans" when Apple posted the same type of graphs, but didn't say a word about what compilers they used, or even what benchmark.

Apple unleashes M1
Apple today announced the biggest leap forward for the Mac with M1, the first system on a chip designed specifically for the Mac.
www.apple.com

Introducing M1 Pro and M1 Max: the most powerful chips Apple has ever built
Apple today announced M1 Pro and M1 Max, the next breakthrough chips for the Mac.
www.apple.com
But nonetheless you are ready to call "shenanigans" ...
I wonder if you also spent so much effort to speculate about compiler flags and other "shenanigans" when Apple posted the same type of graphs, but didn't say a word about what compilers they used, or even what benchmark.
Apple unleashes M1
Apple today announced the biggest leap forward for the Mac with M1, the first system on a chip designed specifically for the Mac.www.apple.com
Introducing M1 Pro and M1 Max: the most powerful chips Apple has ever built
Apple today announced M1 Pro and M1 Max, the next breakthrough chips for the Mac.www.apple.com
And yet Apple’s graphs have been proven accurate, by Ars Technical among others.
Really? How is that possible, given that Apple didn't even say what benchmark was used?And yet Apple’s graphs have been proven accurate, by Ars Technical among others.
Really? How is that possible, given that Apple didn't even say what benchmark was used?
Because the performance slopes are fairly consistent across different benchmarks, so long as the benchmarks are not too specialized. The performance differential on those graphs has been proven to be, if anything, conservative.
Really? According to Apple's graph the M1 Max is supposed to be, what, about 1.7x faster than an 8-core Tiger Lake? And yet the very first M1 Max vs. Tiger Lake benchmark I just found on Google says it's something like 1.1x.Because the performance slopes are fairly consistent across different benchmarks, so long as the benchmarks are not too specialized. The performance differential on those graphs has been proven to be, if anything, conservative.

Apple M1 Max SoC Tackles Intel's Core i9-11900H (Tiger Lake-H Flagship) in Geekbench 5 | Hardware Times
Apple launched its M1 Max SoC the other night with a 10-core CPU and a 32-core GPU the other night for its MacBooks, removing Intel SKUs from the last of its devices. A Geekbench 5 benchmark of the M1 Max was spotted earlier today, and that means it’s time to see just how much faster …
By any chance have you checked out anandtechs breakdown https://www.anandtech.com/show/17024/apple-m1-max-performance-review/4Really? According to Apple's graph the M1 Max is supposed to be, what, about 1.7x faster than an 8-core Tiger Lake? And yet the very first M1 Max vs. Tiger Lake benchmark I just found on Google says it's something like 1.1x.
Apple M1 Max SoC Tackles Intel's Core i9-11900H (Tiger Lake-H Flagship) in Geekbench 5 | Hardware Times
Apple launched its M1 Max SoC the other night with a 10-core CPU and a 32-core GPU the other night for its MacBooks, removing Intel SKUs from the last of its devices. A Geekbench 5 benchmark of the M1 Max was spotted earlier today, and that means it’s time to see just how much faster …www.hardwaretimes.com
They also factored in compilers (and made note of same).
Sure I did and of course i critically evaluated apple claimsBut nonetheless you are ready to call "shenanigans" ...
I wonder if you also spent so much effort to speculate about compiler flags and other "shenanigans" when Apple posted the same type of graphs, but didn't say a word about what compilers they used, or even what benchmark.
Apple unleashes M1
Apple today announced the biggest leap forward for the Mac with M1, the first system on a chip designed specifically for the Mac.www.apple.com
Introducing M1 Pro and M1 Max: the most powerful chips Apple has ever built
Apple today announced M1 Pro and M1 Max, the next breakthrough chips for the Mac.www.apple.com
As cmaier mentioned, apples (albeit vague) graphs lined up if anything conservative with the findings of reputable industry leading tech analyst sites such as anandtech and ars.
Most importantly I didn’t have to rely on Apple’s word for. Day one, apple had their claims verified in detail by many of these outlets.
Apple M1 Pro and M1 Max: Specs, Performance, Everything We Know
Apple takes its fight against Intel to a second round.
Last edited:
But I thought the M1 Max was powerful yet power-efficient. Intel lost the power efficiency on this one
Just for fun …. I decided to spec up a well built workstation laptop from Lenovo. I chose lenovo as (for me) I like the linux support within the community (think wiki) and the ThinkPad P1 is also a thin, light, powerful and well built laptop.
I recently purchased a 16” mbp M1 Max 64GB with 4TB storage.
The equivalent lenovo was much more expensive…

I recently purchased a 16” mbp M1 Max 64GB with 4TB storage.
The equivalent lenovo was much more expensive…
Since laptops have evolved to become appliances integrated in an ecosystem of apps and operating sytem and cloud infrastructure, the priority of having the fastest processor is no longer the main criteria of purchase for many consumers. This is because computing power even in the low end of the market is sufficient today for pretty much all usage except for specialized technical workflows which are better served from dedicated desktops.
Since laptops have evolved to become appliances integrated in an ecosystem of apps and operating sytem and cloud infrastructure, the priority of having the fastest processor is no longer the main criteria of purchase for many consumers. This is because computing power even in the low end of the market is sufficient today for pretty much all usage except for specialized technical workflows which are better served from dedicated desktops.
OK, Chromebook fan.
12th Gen Intel Core processors can use macOS if you use kernel patchThere’s no pressure on Apple because those Intel processors won’t be running macOS or any critical macOS software. Apple’s competition is now Apple’s current systems. As long as their next series processors perform better than the current ones, then anyone who buys them will have the “fastest Mac ever”.
They’ve sidestepped the whole Intel/AMD back and forth.

Register on MacRumors! This sidebar will go away, and you'll see fewer ads.